배깅(Bagging)
- 모두 같은 알고리즘
- 여러 dataset (데이터 중첩 허용)
- ex) 랜덤 포레스트
파라미터
- n_estimators
- 생성할 트리의 개수
- 이 값이 높을수록 모델의 성능이 좋아질 수 있지만, 시간과 메모리 사용량이 증가할 수 있음.
- max_depth
- 트리의 최대 깊이
- 이 값을 높이면 복잡한 모델을 만들 수 있지만, 과적합(overfitting) 문제가 발생할 수 있음.
- min_samples_split
- 노드를 분할하기 위한 최소한의 샘플 데이터 수
- 이 값을 낮추면 노드가 분할되는 빈도가 높아져 모델의 복잡도가 증가할 수 있음
- min_samples_leaf
- 리프 노드가 되기 위한 최소한의 샘플 데이터 수
- 이 값을 높이면 모델이 학습하는 데 사용되는 데이터 수가 줄어들어 일반화 성능이 향상될 수 있음
- max_features
- 각 노드에서 선택될 후보 특성의 개수
- 이 값을 높이면 모델의 다양성이 감소하고, 낮추면 모델이 더 다양해져 과적합 문제가 감소할 수 있음
- bootstrap
- 트리를 학습할 때, 데이터 샘플링을 수행할지 여부를 결정
- True로 설정하면 복원 추출(bootstrapping)을 수행
유방암 데이터 세트
from sklearn.model_selection import train_test_split
X_train , X_test , y_train , y_test = train_test_split(
data_df.drop("target", axis=1),
data_df['target'],
random_state=42
)
랜덤 포레스트
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
params = {'n_estimators':[10,100]}
rf_grid_search = GridSearchCV(RandomForestClassifier(random_state=42),
param_grid = params,
scoring = 'accuracy',
cv = 5)
rf_grid_search.fit(X_train, y_train)
# GridSearchCV객체의 cv_results_ 속성을 DataFrame으로 생성.
cv_results_df = pd.DataFrame(rf_grid_search.cv_results_)
# max_depth,min_samples_split 파라미터 값과 그때의 테스트(Evaluation)셋, 학습 데이터 셋의 정확도 수치 추출
cv_results_df[['param_n_estimators', 'mean_test_score']]
특성 중요도
import matplotlib.pyplot as plt
import seaborn as sns
def plot_feature_importance(model, columns, limit=None):
ftr_importances_values = model.feature_importances_
ftr_importances = pd.Series(ftr_importances_values, index=columns)
ftr_top = ftr_importances.sort_values(ascending=False)[:limit]
plt.figure(figsize=(8,6))
plt.title(f'Feature importacnes Top {len(columns if limit ==None else limit}')
sns.barplot(x=ftr_top, y=ftr_top.index)
plt.show()
plot_feature_importance(rf_grid_search.best_estimator_, X_train.columns)
 특성 중요도_random forest
특성 중요도_random forest
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
params = {
'max_depth' : [8, 12, 16 ,20],
'min_samples_split' : [16, 24],
}
dt_grid_search = GridSearchCV(
DecisionTreeClassifier(random_state=42),
param_grid=params,
cv=5,
scoring='accuracy'
)
dt_grid_search.fit(X_train, y_train)
plot_feature_importance(dt_grid_search.best_estimator_, X_train.columns)
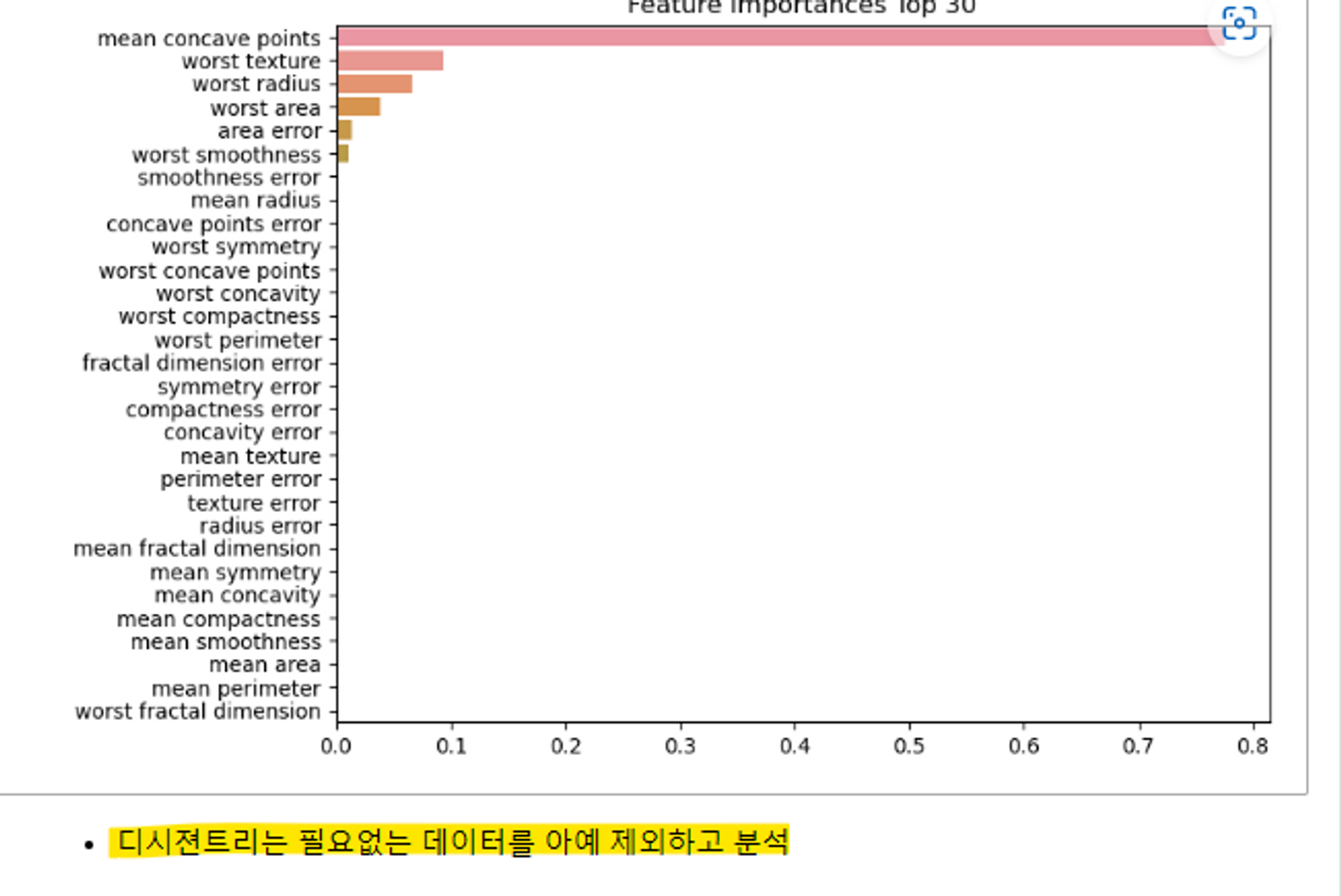 특성 중요도_decision tree
특성 중요도_decision tree
