
데이터로그😎
[분류] 신용카드 사기 검출 본문
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
card_df = pd.read_csv('creditcard.csv')
card_df
데이터 전처리 & 스케일러 함수
from sklearn.preprocessing import StandardScaler
def get_preprocessed_df(df=None):
df_copy = df.copy()
scaler = StandardScaler()
amount_n = scaler.fit_transform(df_copy['Amount'].values.reshape(-1,1))
df_copy.insert(0,'Amount_Scaled',amount_n)
df_copy.drop(['Time','Amount'],axis=1, inplace=True)
return df_copy
데이터 분할 함수
from sklearn.model_selection import train_test_split
def get_train_test_dataset(df=None):
df_copy = get_preprocessed_df(df)
X_features = df_copy.iloc[:,:-1]
y_target = df_copy.iloc[:,-1]
X_train, X_test, y_train, y_test = train_test_split(X_features, y_target, test_size=0.3, random_state=0, stratify=y_target)
return X_train, X_test, y_train, y_test
평가 함수
from sklearn.metrics import accuracy_score, f1_score, roc_auc_score, precision_score, recall_score, r2_score, confusion_matrix
def get_clf_eval(y_test, lr_pred, pred_proba=None):
acc = accuracy_score(y_test, lr_pred)
conf = confusion_matrix(y_test, lr_pred)
pre = precision_score(y_test, lr_pred)
recall = recall_score(y_test, lr_pred)
f1 = f1_score(y_test, lr_pred)
auc = roc_auc_score(y_test, pred_proba)
print(f'정확도: {acc}')
print(f'오차행렬: {conf}')
print(f'정밀도 {pre}')
print(f'재현율 {recall}')
print(f'f1: {f1}')
print(f'auc : {auc}')
return acc, conf, pre, recall, f1, auc
학습 함수
def get_model_train_eval(model, ftr_train=None, ftr_test=None, tgt_train = None, tgt_test=None):
model.fit(ftr_train, tgt_train)
pred = model.predict(ftr_test)
pred_proba = model.predict_proba(ftr_test)[:,1]
get_clf_eval(tgt_test, pred, pred_proba)
로지스틱, LGBM
from sklearn.linear_model import LogisticRegression
from lightgbm import LGBMClassifier
lr = LogisticRegression(max_iter = 1000)
get_model_train_eval(lr, X_train, X_test, y_train, y_test)
lgbm_clf = LGBMClassifier(n_estimators = 1000, num_leaves=64, n_jobs=1, boost_from_average=False)
get_model_train_eval(lgbm_clf, X_train, X_test, y_train, y_test)logistic보다 lightgbm이 모든 평가수치가 조금씩 높게나옴.
성능 개선 위해 왜곡된 분포 분석
import seaborn as sns
plt.figure(figsize=(8,4))
plt.xticks(range(0,30000, 1000), rotation=60)
sns.histplot(card_df['Amount'],bins=100, kde=True)
plt.show()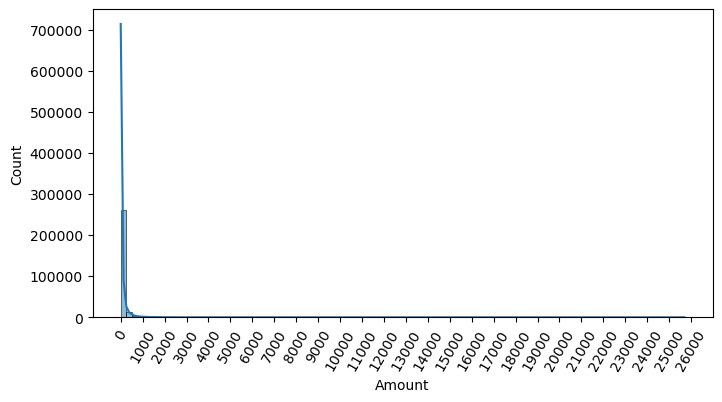
꼬리가 긴 형태를 띄고 있다.
amount(사용금액)이 대부분은 1000 이하이지만 그 이상 사용금액이 드물게 발생함.
왜곡된 분포 개선을 위해
log변환을 해보겠음.
로그변환 함
def get_preprocessed_df(df=None):
df_copy = df.copy()
amount_n = np.log1p(df_copy['Amount'])
df_copy.insert(0,'Amount_Scaled',amount_n)
df_copy.drop(['Time','Amount'],axis=1, inplace=True)
return df_copy
로그 변환 후
로지스틱은 정밀도 향상, 재현율 저하.
lgbm은 재현율 향상
-----------
극도의 불균일한 데이터에서는 로지스틱 회귀가 약간 불안정?
이상치 제거 함수
def get_outlier(df=None, column=None, weight=1.5):
fraud = df[df['Class']==1][column]
quantile_25 = np.percentile(fraud.values, 25)
quantile_75 = np.percentile(fraud.values, 75)
iqr = quantile_75-quantile_25
iqr_weight = iqr*weight
lowest_val = quantile_25-iqr_weight
highest_val = quantile_75+iqr_weight
outlier_index = fraud[(fraud<lowest_val)|(fraud>highest_val)].index
return outlier_index'머신러닝 > Kaggle' 카테고리의 다른 글
| [분류] 자전거대여 수요예측 (0) | 2023.09.05 |
|---|
'머신러닝/Kaggle' Related Articles
more
