
데이터로그😎
[Spark] Spark Machine-Learning 본문
- 데이터 생성
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
# iris datasets 로딩
iris = load_iris()
iris_data = iris.data # feature
iris_label = iris.target # label
iris_columns = ["sepal_length", "sepal_width", "petal_length", "petal_width"]
iris_pdf = pd.DataFrame(iris_data, columns=iris_columns)
iris_pdf['target'] = iris_label
iris_pdfspark ml에서도 사용할 수 있도록 iris_pdf는 csv로 저장해놓겠다.
iris_pdf.to_csv('./data/iris.csv', index=False)
사이킷런 모델
- 모델 학습, 예측
# 데이터 분할 및 모델 생성
# from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier # Estimator
from sklearn.model_selection import train_test_split # RandomSpliter
X_train, X_test, t_train, t_test = train_test_split(
iris_data,
iris_label,
test_size=0.2,
random_state=42
)
tree_clf = DecisionTreeClassifier()
tree_clf.fit(X_train, t_train) # 훈련! tree_clf 모델 자체에서 훈련이 일어나게 된다.
pred = tree_clf.predict(X_test)
print(pred)
Spark ML
데이터 준비
- 데이터 가져오기
from pyspark.sql import SparkSession
spark = SparkSession.builder.master('local').appName('tree-clf').getOrCreate()
iris_filepath = "/home/ubuntu/working/spark-examples/data/iris.csv"
iris_sdf = spark.read.csv(f'file://{iris_filepath}',
inferSchema = True,
header = True)
iris_sdf.show(5)
- 데이터 쪼개기(학습, 테스트)
# randomSplit 메소드를 활용해 훈련/ 테스트 데이터 세트 분할
train_sdf, test_sdf = iris_sdf.randomSplit([0.8,0.2], seed=42)
VectorAssembler
- `VectorAssembler` 를 이용해 모든 feature 컬럼을 하나의 feature vector로 만든다.(행벡터)
- inputCols는 하나로 묶을 컬럼들의 이름들, outputCol은 최종으로 하나로 묶여서 벡터로 나오게될 컬럼의 이름
- train data와 test data 모두 vector화 한다.
from pyspark.ml.feature import VectorAssembler
# VectorAssembler 로 데이터프레임에 있는 데이터를 하나의 행벡터로 합쳐준다.
# inputCols = 합칠 컬럼의 목록들
# outputCol = 데이터가 합쳐진 컬럼의 이름. assemble이 완료된 컬럼
iris_columns = ["sepal_length", "sepal_width", "petal_length", "petal_width"]
# inputCols에 집어넣은 컬럼들이 outputCol인 features라는 이름으로 벡터로 묶일 것
vec_assembler = VectorAssembler(inputCols=iris_columns, outputCol = 'features')
# VectorAssembler Transform
train_feature_vector_sdf = vec_assembler.transform(train_sdf)
train_feature_vector_sdf.show(5)
# 훈련 데이터에서 적용시켰던 Transformer를 테스트 세트에다가도 그대로 적용시킨다.
test_feature_vector_sdf = vec_assembler.transform(test_sdf)
test_feature_vector_sdf.show(5)
모델생성
from pyspark.ml.classification import DecisionTreeClassifier
# 모델 생성: "데이터 프레임의 어떤 컬럼"의 데이터를 이용해서 학습을 할지 결정 지어줘야 한다.
dt = DecisionTreeClassifier(
featuresCol = 'features',
labelCol = 'target',
maxDepth = 2,
)
type(dt)
학습
# 모델 학슴. fit() 메소드를 이용하여 학습을 수행하고, 그 결과를 ML 모델로 변환한다.
dt_model = dt.fit(train_feature_vector_sdf)
type(dt_model)
예측
# 예측
predictions = dt_model.transform(test_feature_vector_sdf)
predictions.show()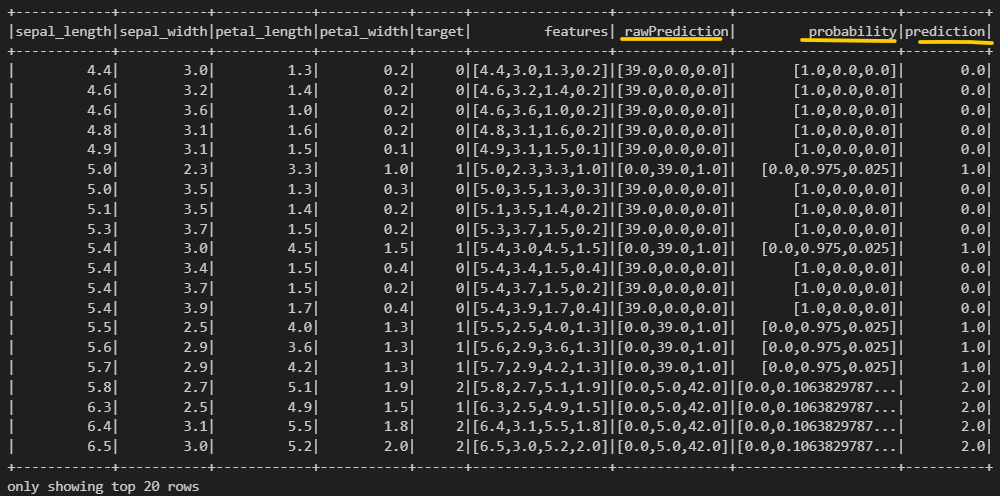
- rawPrediction: 각 붓꽃 종류에 대한 예측 점수
- probability: 각 붓꽃 종류에 대한 예측 확률
- prediction: 예측된 붓꽃 종류의 레이블
- iris.target_names를 보면 (['setosa', 'versicolor', 'virginica'], 꽃 종류는 이렇게 세가지
- `rawPrediction`: 머신러닝 모델 알고리즘 별로 다를 수 있다.
- 머신러닝 알고리즘에 의해 계산된 값
- 값에 대한 정확한 의미는 없음.
- `LogisticRegression` 의 경우 예측 label 별로, 예측 수행 전 `sigmoid` 함수 적용 전 값
평가
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
evaluator_accuracy = MulticlassClassificationEvaluator(
labelCol='target',
predictionCol='prediction',
metricName = 'accuracy'
)
accuracy = evaluator_accuracy.evaluate(predictions)
accuracy # maxDepth 수 많아지면 정확도 올라가는 경향?
Spark ml -> 파이프라인 만들기
from pyspark.ml import Pipeline
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.classification import DecisionTreeClassifier
iris_columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
# Pipeline은 개별 변환 및 모델 학습 작업을 각각의 stage로 정의해서 파이프라인에 순서대로 등록
# Pipeline.fit() 메소드를 활용해서 순서대로 연결된 스테이지 작업을 일괄적으로 수행
# Pipeline.fit()의 결과물은 PipelineModel로 반환이 된다.
# PipelineModel에서 예측 작업을 transform()으로 수행
# 첫 번째 stage는 Feature Vectorization을 위한 VectorAssembler
stage_1 = VectorAssembler(inputCols=iris_columns, outputCol = 'features')
# 두번째 stage는 학습을 위한 모델 생성
stage_2 = DecisionTreeClassifier(featuresCol='features', labelCol='target', maxDepth = 3)
# 리스트를 활용해 stage를 순서대로 배치
stages = [ stage_1, stage_2 ]
# 파이프라인에 등록
pipeline = Pipeline(stages = stages)
type(pipeline)
pipeline_model = pipeline.fit(train_sdf)
# 파이프라인을 통해서 테스트 세트 예측
predictions = pipeline_model.transform(test_sdf)
predictions.show(5)'Data Engineering' 카테고리의 다른 글
| [Linux] 1. 리눅스 기초 (0) | 2024.01.14 |
|---|---|
| [Spark] Spark SQL에서 날짜 형식 중 년, 월, 일 따로 추출하는 법! (0) | 2023.09.15 |
| [Spark] Spark SQL (0) | 2023.09.14 |
| [Spark] Spark RDD (0) | 2023.09.14 |
| 분산 병렬 처리 시스템 (MPP, DFS) (0) | 2023.09.14 |
'Data Engineering' Related Articles
more

