
목록Data Engineering (23)
데이터로그😎
 [Linux] 4. 디렉토리 구조와 파일 찾기
[Linux] 4. 디렉토리 구조와 파일 찾기
디렉토리 구조 참조: https://www.thegeekstuff.com/2010/09/linux-file-system-structure/ linux에서 root 위치에서 pwd를 실행하면 / 라고 뜬다. 이 때 root의 하위 디렉토리들을 살펴보자. (base) ubuntu@JeeYeon:/$ tree -L 1 . ├── bin -> usr/bin ├── boot ├── dev ├── etc ├── home ├── init ├── lib -> usr/lib ├── lib32 -> usr/lib32 ├── lib64 -> usr/lib64 ├── libx32 -> usr/libx32 ├── lost+found ├── media ├── mnt ├── opt ├── proc ├── root ├── run ├..
 [Linux] 3. Shell & Shell script
[Linux] 3. Shell & Shell script
Kernel & Shell hardware - 물리적인 컴퓨터 시스템의 구성요소 - 메모리, 하드디스크, SSD, CPU Kernel - 운영체제의 핵심 부분 - 하드웨어와 소프트웨어 간의 통신을 담당 - 시스템 리소스 관리 - Window 커널, Linux 커널, macOS 커널 등 Shell - 사용자와 운영체제 간의 중개자 - 명령어를 해석하고 실행하여 사용자에게 서비스 제공 - 명령어를 해석하여 kernel에 전달 - Bash, Zsh, Fish Applications - 사용자가 직접 상호작용하거나 업무를 수행하는 소프트웨어 어플리케이션 - 텍스트 편집기, 웹 브라우저, 게임, 그래픽 소프트웨어 Shell: bash vs zsh cd + 스페이스바 + tab 2번 cd를 입력후 스페이스바 한 번..
 [Linux] 2. IO Redirection - output
[Linux] 2. IO Redirection - output
Unix Process Standard Input = 명령어 (예: ls-l) Standard Input의 결과물 의 종류 (Output의 종류) Standard Output 예를 들면, Input으로 ls -l 명령어를 입력했다면 "현재 디렉토리에 위치한 파일명을 출력" 한 것이 output이 된다. 기본적으로 모니터에 output이 출력된다. Standard Error 만약 Input의 명령어가 잘못되었다면? Error가 출력된다. Redirection - output Redirection 이란? 리눅스에서의 리다이렉션은 명령어의 입력이나 출력을 다른 위치로 전환하거나 저장하는 것을 의미합니다. 쉘에서 사용되는 명령어의 입출력을 조절하는 데 사용됩니다. 주로 파일 또는 다른 프로세스와의 통신에 활용됩..
 [Linux] 1. 리눅스 기초
[Linux] 1. 리눅스 기초
GUI & CLI GUI (Graffic User Interface) 특징 그래픽 요소를 사용하여 사용자와 시스템 간의 상호 작용을 제공합니다. 일반적으로 아이콘, 버튼, 창, 메뉴 등의 시각적 요소를 포함합니다. 마우스를 사용하여 작업을 수행하며, 시각적으로 직관적이고 사용하기 쉽습니다. 일반적으로 더 많은 리소스를 사용하며, 높은 수준의 편의성을 제공합니다. 예시 Windows, macOS, Ubuntu Desktop 등의 운영 체제에서의 데스크톱 환경. CLI (Command Line Interface) 특징 명령어를 텍스트로 입력하여 시스템과 상호 작용합니다. 주로 키보드를 사용하며, 명령어를 통해 작업을 수행합니다. 자원 사용량이 적고, 일반적으로 빠른 작업이 가능합니다. 학습 곡선이 높을 수 ..
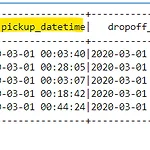 [Spark] Spark SQL에서 날짜 형식 중 년, 월, 일 따로 추출하는 법!
[Spark] Spark SQL에서 날짜 형식 중 년, 월, 일 따로 추출하는 법!
spark3.0이 도입되면서 약간 룰이 달라졌다. 지금부터 도입 이전, 후에 어떻게 달라졌는지 알아보겠다. Spark 3.0 이전 from pyspark.sql import SparkSession spark = SparkSession.builder.appName('trip').getOrCreate() filepath = '/home/ubuntu/working/spark-example/data/fhvhv_tripdata_2020-03.csv' taxi_df = spark.read.csv(f'file:///{filepath}', inferSchema=True, header= True) taxi_df.show(5) 한 번 데이터 프레임의 데이터 형식을 알아볼까? taxi_df.printSchema() ####..
 [Spark] Spark Machine-Learning
[Spark] Spark Machine-Learning
데이터 생성 from sklearn.datasets import load_iris import pandas as pd import numpy as np # iris datasets 로딩 iris = load_iris() iris_data = iris.data # feature iris_label = iris.target # label iris_columns = ["sepal_length", "sepal_width", "petal_length", "petal_width"] iris_pdf = pd.DataFrame(iris_data, columns=iris_columns) iris_pdf['target'] = iris_label iris_pdf spark ml에서도 사용할 수 있도록 iris_pdf는 cs..
데이터 불러오기 from pyspark.sql import SparkSession # spark session 생성 spark = SparkSession.builder.master('local').appName('spark-sql').getOrCreate() movies = [ (1, "어벤져스", "마블", 2012, 4, 26), (2, "슈퍼맨", "DC", 2013, 6, 13), (3, "배트맨", "DC", 2008, 8, 6), (4, "겨울왕국", "디즈니", 2014, 1, 16), (5, "아이언맨", "마블", 2008, 4, 30) ] # RDD movie_schema = ["id", "name", "company", "year", "month", "day"] attendances ..
1. Resilient Distributed Dataset(RDD) 스파크에서 사용하는 데이터의 최소단위. 판다스에 넘파이가 있다면 spark sql, df에는 rdd가 있다! # 특징 RDD = 스파크의 핵심 데이터 모델 cluster에 있는 worker 의 메모리 안쪽에 RDD가 위치함. worker들의 메모리에 RDD가 쪼개져서 위치함. 각 RDD들은 서로 연관이 있음. 변경이 불가. Inplace 불가. 작업을 할 때마다 새로운 RDD를 계속 만들게 됨. 데이터 추상화 여러군데에 쪼개져있는 파일을 마치 하나의 파일처럼 사용할 수 있도록 추상화 함. 파일을 하나하나 신경써서 일일이 불러오는게 아니고 tool이 알아서 파악해서 불러옴. 100PB파일을 여러개의 HDFS에 분산되어 저장 HDFS에 분산..