
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 팔방이익구조
- 코호트
- model_selection
- 서말리포켓
- 전환율
- 올라
- 핀테크
- 선정산서비스
- 한장으로끝내는비즈니스모델100
- 인게이지먼트
- BM분석
- 머신러닝
- sklearn
- 비즈니스모델
- mysql설치 #mysql #mysqluser #mysqlworkbench
- allra
- retention
- 그로스해킹
- CAC
- 데이터분석
- 리텐션
- pmf
- 역설구조
- aarrr
- 활성화
- fundbox
- 퍼널분석
- 바로팜
- activation
- 셀프스토리지
Archives
- Today
- Total
데이터로그😎
[지도학습] 1. 선형 회귀 (Linear Regression) 본문
- 선형 - 비선형 회귀의 구분
- 회귀계수가 선형인지 비선형인지에 따름
- 선형: 선형회귀
- 비선형: 딥러닝, 트리...
- 독립변수의 선형, 비선형 여부와는 무관
- 회귀계수가 선형인지 비선형인지에 따름
| 규제 적용X | 규제 적용O |
|
|
| 파라미터 | 속성 |
|
|
✅<규제 X 선형회귀>
1. 단순 선형회귀
- 독립변수 1, 종속변수 1
- y = w0 + w1*x + 오류값(잔차)
- 독립변수 = feature
- 종속변수(결과) = target, label
- 목표: RSS 최소화 (잔차값 최소화).
- 최적 회귀 모델을 만든다는 것 = 잔차의 합이 최소가 되는 회귀 계수를 찾는 것.
- 회귀계수(coefficient, 가중치) = 각 featrue(특성)이 결과값에 미치는 영향력의 크기
1-1. 데이터 불러오기
- 보스턴 주택가격 예측
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import warnings
warnings.filterwarnings('ignore') # 사이킷런 1.2 부터는 보스턴 주택가격 데이터가 없어진다는 warning 메시지 출력 제거
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
boston_df = pd.DataFrame(
data=data,
columns=['CRIM','ZN','INDUS','CHAS','NOX','RM','AGE','DIS','RAD','TAX','PTRATIO','B','LSTAT']
)
boston_df['PRICE']=target
boston_df
1-2. 데이터 상관관계 확인
- heatmap
boston_df.corr()['PRICE'].sort_values()
#히트맵으로 확인
# Feature끼리의 상관관계 확인
# 너무 많은 상관성을 가진 데이터를 확인할 수 있다. -> 다중공선성
plt.figure(figsize=(10,10))
corr_df = boston_df.corr()
sns.heatmap(
data = corr_df,
annot = True)
plt.show()- regplot: 산점도+선형회귀 직선 (독립-종속변수 간의 관계를 모든 컬럼마다 그려줌)
fig, axs=plt.subplots(figsize=(20,10),ncols=4,nrows=2)
features = ['RM','ZN','INDUS','NOX','AGE','PTRATIO','LSTAT','RAD']
for i, feature in enumerate(features):
row = int(i/4)
col = i%4
sns.regplot(x=feature, y='PRICE',data=boston_df,ax=axs[row][col])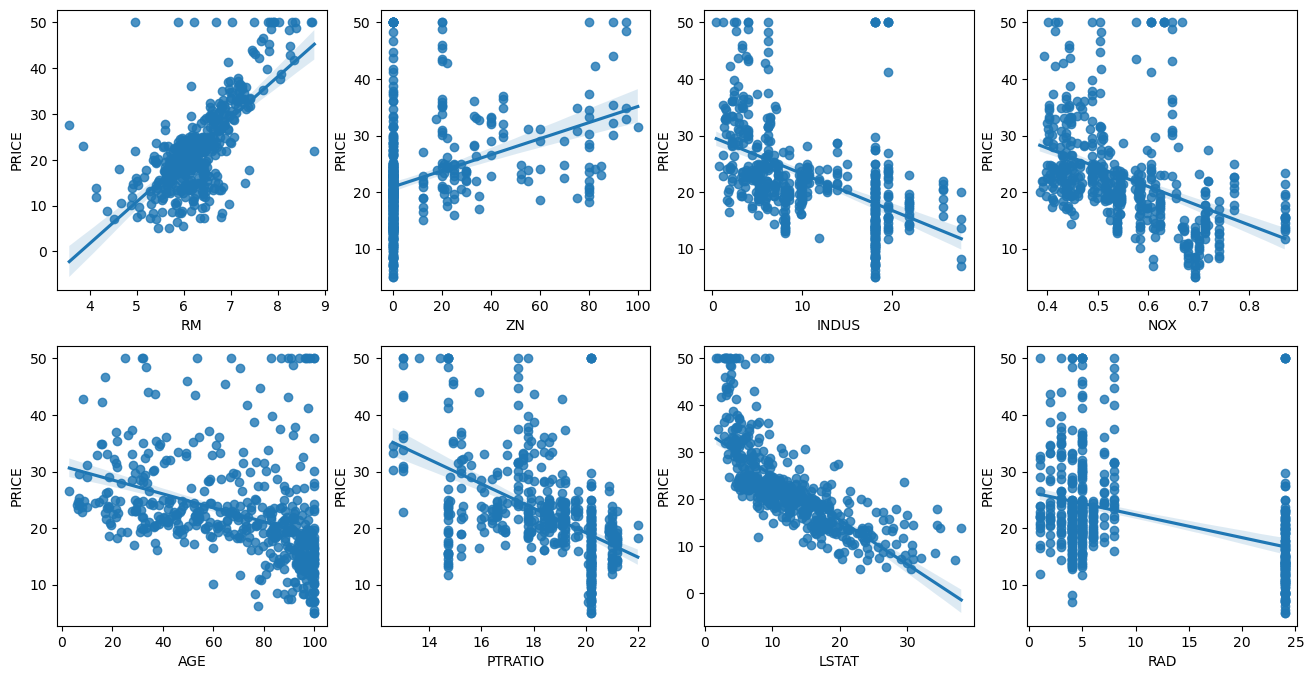
regplot을 해석해보면 RM, LSTAT의 PRICE 영향도가 큼.
RM = 양방향의 선형성, LSTAT = 음의 방향의 선형성
1-3. 데이터 분할 & 모델 훈련
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
X_train, X_test, y_train, y_test = train_test_split(
boston_df.drop('PRICE', axis =1), # 13개 features
boston_df['PRICE'],
test_size = 0.2,
random_state = 42
)
lr_reg = LinearRegression()
lr_reg.fit(X_train, y_train)1-4. 모델 학습결과 확인: 가중치(.coef_), 편향(.intercept_)
# 가중치, 편향 (모델 파라미터) 확인
# 모델 파라미터: 학습하면서 데이터가 스스로 배우는 것
# 하이퍼 파라미터: 개발자가 직접 넣어야하는 것
print('가중치 \:{}'.format(lr_reg.coef_),end='\n\n') #.coef_ : 기울기
print('편향 b: {}'.format(lr_reg.intercept_)) #.interceipt_ : 절편
>>> 가중치: [-0.1 0.1 0. 3....]
>>> 편향: 40,9955....
- 추가로 coef_만 따로 뽑아내서 확인할 수도 있다.
print(f'회귀계수: {np.round(lr_reg.coef_,1)}')
print()
print(f'절편: {lr_reg.intercept_}')
>>>회귀계수: [ -0.1 0.1 0. 3. -19.8 3.4 0. -1.7 0.4 -0. -0.9 0.
-0.6]
절편: 40.995595172164336coeff=pd.Series(np.round(lr.coef_,1),index= boston_df.drop('PRICE',axis=1).columns)
coeff.sort_values(ascending=False)
<>>>>
RM 3.4
CHAS 3.0
RAD 0.4
ZN 0.1
INDUS 0.0
AGE 0.0
TAX -0.0
B 0.0
CRIM -0.1
LSTAT -0.6
PTRATIO -0.9
DIS -1.7
NOX -19.8
dtype: float641-5. 평가
from sklearn.metrics import mean_squared_error, r2_score
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse) # mse에 루트씌우면 mse
r2 = r2_score(y_test, y_pred) # accuracy_score와 같은 기능. 즉 모델의 점수 개념! model.score로 구할 수 있다
print('MSE: {:.3f}'.format(mse))
print('RMSE: {:.3f}'.format(rmse))
print()
print('R2: {:.3f}'.format(r2))
print('Score: {:.3f}'.format(lr_reg.score(X_test, y_test)))
#r2와 score값 동일!!
------------------------------------------
MSE: 24.291
RMSE: 4.929
R2: 0.669 (accuracy_score와 비슷)
Score: 0.669
2. 다항회귀 (Polynomial)
- 다항회귀는 선형회귀임
- 1차식이 아닌 2,3차 방정식으로 표현되는 회귀식
- 사이킷런에서는 다항회귀를 위한 클래스를 명시적으로 제공하진 x. 따라서 다항피처로 변환 후 선형회귀 클래스 사용.
- 다항회귀는 PolynomiaFeatures 클래스를 통해 X_train데이터를 다항식 피처로 변환후 훈련(fit)한다.
- 그 후 X_test데이터도 Poly로 변환해줌
- 순서: X_train데이터 다항식피처로 변환 →모델학습(fit)→ X_test데이터도 변환 → 변환한 X_test데이터로 predict → mse,rmse,r2 산출
- 파라미터
- degree : 다항식의 차수를 나타내는 파라미터입니다. 예를 들어, degree=2로 설정하면 2차 다항식 특성이 추가됩니다.
- include_bias : 상수항을 추가할지 여부를 결정하는 파라미터입니다. 기본값은 True로, 상수항이 추가됩니다.
2-1. X_train 데이터 -> 3차식 변환
from sklearn.preprocessing import PolynomialFeatures
boston_poly = PolynomialFeatures(degree=3, include_bias = False)
#3차식으로 변형된 X_train =X_poly_3
X_poly_3 = boston_poly.fit_transform(X_train)
X_train.shape, X_poly_3.shape
#원래 13개 피쳐를 갖고 있던 X_train이 poly변환을 통해 559피처로 증가
>>>((404, 13), (404, 559))
2-2. 학습 (using X_poly_3)
lr_reg_poly = LinearRegression().fit(X_poly_3, y_train)
# 먼저 X_train -> 3차 다항식으로 X_poly_3로 변환한뒤 fit해서 학습
2-3. X_test ->3차식 변형
X_poly_test3 = boston_poly.fit_transform(X_test)
2-4. 예측
y_test_pred = lr_reg_poly.predict(X_poly_test3)
test_mse = mean_squared_error(y_test, y_test_pred)
test_rmse = np.sqrt(test_mse)
test_r2 = r2_score(y_test, y_test_pred)
print('Test MSE: {:.3f}'.format(test_mse))
print('Test RMSE: {:.3f}'.format(test_rmse))
print('Test R2: {:.3f}'.format(test_r2))
# 3차 다항식으로 구하니 말도 안되는...오류 수치들이 나옴
# 엄청난 과대적함...
>>Test MSE: 129848.080
Test RMSE: 360.344
Test R2: -1769.645
2-5. 2차 다항회귀
from sklearn.preprocessing import PolynomialFeature
from sklearn.linear_model import LinearRegression
# 2차 다항식으로 변경
boston_poly = PolynomialFeature(degree=2, include_bias = False)
X_poly_2 = boston_poly.fit_transform(X_train)
# 학습
lr_reg_poly = LinearRegression().fit(X_poly_2, y_train)
# X_test 데이터 변형
X_poly_test2 = boston_poly.fit_transform(X_test)
# predict
y_test_pred2 = lr_reg_poly.predict(X_poly_test2)
# 평가
test_mse = mean_squared_error(y_test, y_test_pred2)
test_rmse = np.sqrt(test_mse)
test_r2 = r2_score(y_test, y_test_pred2)
print('Test MSE: {:.3f}'.format(test_mse))
print('Test RMSE: {:.3f}'.format(test_rmse))
print('Test R2: {:.3f}'.format(test_r2))
>>>결과:
Test MSE: 14.257
Test RMSE: 3.776
Test R2: 0.806
# 일반 선형회귀 사용 때보다 다항회귀를 사용하니 오류 줄고 R2 상승.⭐⭐다항식의 차수가 높아질 수록 과적합의 문제 발생!!!⭐
degree=1 → 너무 단순화된 곡선. 과소적합
degree=15 → 과적합. 회귀계수가 너무 커져서 형편없는 예측성능
❓일반 선형회귀의 문제점?
- 위의 2-4에서 볼 수 있듯이, 다항회귀에서는 차수가 낮으면 지나치게 곡선이 단순화되어 과소적합, 차수가 높으면 지나치게 모든 데이터에 적합해져 다항식이 복잡 & 회귀계수 매우 크게 설정되어 예측성능↓
- 따라서 회귀 모델은 데이터에 적합하며 회귀 계수가 커지는 것을 제어할 수 있어야 함.
- 회귀계수가 커진다? → 해당 feature가 결과값에 큰 영향을 미치게 되어 그 feature값을 조정하면 결과값이 크게 바뀔 수 있다는 것을 의미. 즉, 해당 feature가 예측에 매우 중요하다는 의미.
- 그러나 모델이 학습 데이터에 지나치게 맞추게 되면 회귀계수가 커져서 모델이 지나치게 학습 데이터에만 특화→따라서 회귀모델은 회귀계수가 기하급수적으로 커지는 것을 제어할 수 있어야 함.
- 일반 선형 모델에서는 RSS를 최소화하는 것만 고려. -> 지나치게 학습 데이터에 맞추게 되면 잔차가 작아지는 방향으로 회귀계수가 커짐 = overfitting -> 새로운 데이터에 대한 예측 성능 저하.
- 이를 막기 위해, 비용함수는 RSS 최소화 + 회귀 계수 값 제어가 균형을 이루어 모델이 학습 데이터에만 과적합 되는 것을 방지 필요가 있음. 👉 규제 선형모델
✅<규제 선형모델>
- 비용함수에서 alpha값으로 페널티를 부여하여 회귀계수 값의 크기를 감소시켜 과적합을 개선하는 방식
- 라쏘 (L1 규제) : 회귀계수 0으로 만들 수 있음 (변수 선택한다는 관점)
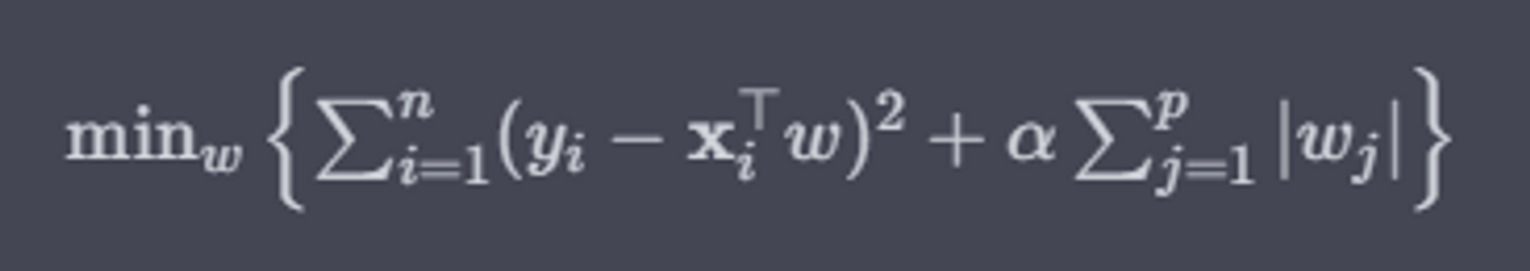
- 릿지 (L2 규제): 회귀계수 크기 제한

- alpha는 회귀 계수값의 크기를 제어하는 튜닝 파라미터
- alpha=0 → 기존의 비용함수와 동일해짐
- alpha 값을 크게 → 비용함수는 회귀계수 W의 값을 작게함→ 과대적합 개선
- alpha 값 작게 → W의 값이 커져도 어느정도 상쇄 가능 → 데이터 적합을 개선할 수 음
1. 릿지회귀(L2): 회귀계수 크기 제한
보스턴 주택가격 분석
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import warnings
warnings.filterwarnings('ignore') # 사이킷런 1.2 부터는 보스턴 주택가격 데이터가 없어진다는 warning 메시지 출력 제거
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
boston_df = pd.DataFrame(
data=data,
columns=['CRIM','ZN','INDUS','CHAS','NOX','RM','AGE','DIS','RAD','TAX','PTRATIO','B','LSTAT']
)
boston_df['PRICE']=target
boston_df
Poly (X) + alpha = 10일때
from sklearn.linear_model import Ridge
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
X = boston_df.drop('PRICE',axis=1)
y = boston_df['PRICE']
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.2,
random_state = 42)
# 릿지 생성
lr_ridge = Ridge(alpha=10)
# alpha는 log scale로 지정하는게 보통(0.01,0.1,10,100...10^n)
lr_ridge.fit(X_train, y_train)
# 예측, 평가
ridge_pred = lr_ridge.predict(X_test)
mse = mean_squared_error(y_test, ridge_pred)
rmse = np.sqrt(mse)
r2 = lr_ridge.score(X_test, y_test)
print('MSE: {:.3f}'.format(mse))
print('RMSE: {:.3f}'.format(rmse))
print('R2: {:.3f}'.format(r2))
# 12. 선형회귀의 '평가'부분의 결과보다 MSE, RMSE 늘어났음 = 모델이 단순해진 것.
# = 성능 떨어짐 = 규제 풀어주는 게 좋을 것 (alpha를 0에 가깝게 만드는 것)
>>>MSE: 24.648
RMSE: 4.965
R2: 0.6642차 다항 선형회귀보다 성능이 안좋아짐(오류 늘어남) -> 과대적합 되었다는 말? -> 회귀계수가 커졌다 -> alpha를 줄여서 과대적합 줄여보자!
Poly(X) + alpha = 0일때
lr_ridge = Ridge(alpha=0)
# alpha는 log scale로 지정하는게 보통(0.01,0.1,10,100...10^n)
lr_ridge.fit(X_train, y_train)
ridge_pred = lr_ridge.predict(X_test)
mse = mean_squared_error(y_test, ridge_pred)
rmse = np.sqrt(mse)
r2 = lr_ridge.score(X_test, y_test)
print('MSE: {:.3f}'.format(mse))
print('RMSE: {:.3f}'.format(rmse))
print('R2: {:.3f}'.format(r2))
>>>MSE: 24.291
RMSE: 4.929
R2: 0.669alpha가 0이면 그냥 Linear Regression이랑 똑같은 것임
- 즉, 내가 alpha를 아무리 건드려서 줄여봐도 Linear Regression의 성능을 넘을 순 없음
- 따라서 이제 데이터 공학이 필요한 때 -> degree=3으로 조정
Poly 3차원(O) + 릿지 규제
from sklearn.preprocessing import PolynomialFeatures
from sklearn.metrics import r2_score
boston_poly = PolynomialFeatures(degree=3, include_bias =False)
X_train_3 = boston_poly.fit_transform(X_train)
X_test_3 = boston_poly.transform(X_test)
# 훈련 데이터에 대한 예측
lr_train_pred = lr.predict(X_train_3)
ridge_train_pred = lr_ridge.predict(X_train_3)
# 평가
## 일반 선형회귀
lr_train_mse = mean_squared_error(y_train, lr_train_pred)
lr_train_rmse = np.sqrt(lr_train_mse)
lr_train_r2 = r2_score(y_train, lr_train_pred)
## 릿지 규제
ridge_train_mse = mean_squared_error(y_train, ridge_train_pred)
ridge_train_rmse = np.sqrt(ridge_train_mse)
ridge_train_r2 = r2_score(y_train, ridge_train_pred)
print("LinearRegression MSE : {:.3f} / RMSE : {:.3f} / R2 : {:.3f}".format(lr_train_mse, lr_train_rmse, lr_train_r2))
print("Ridge MSE : {:.3f} / RMSE : {:.3f} / R2 : {:.3f}".format(ridge_train_mse, ridge_train_rmse, ridge_train_r2))
>>>LinearRegression MSE : 0.000 / RMSE : 0.000 / R2 : 1.000
Ridge MSE : 19.070 / RMSE : 4.367 / R2 : 0.780# 테스트 세트 확인
lr_test_pred = lr.predict(X_test_3)
ridge_test_pred = lr_ridge.predict(X_test_3)
lr_test_mse = mean_squared_error(y_test, lr_test_pred)
lr_test_rmse = np.sqrt(lr_test_mse)
lr_test_r2 = r2_score(y_test, lr_test_pred)
ridge_test_mse = mean_squared_error(y_test, ridge_test_pred)
ridge_test_rmse = np.sqrt(ridge_test_mse)
ridge_test_r2 = r2_score(y_test, ridge_test_pred)
print("LinearRegression MSE : {:.3f} / RMSE : {:.3f} / R2 : {:.3f}".format(lr_test_mse, lr_test_rmse, lr_test_r2))
print("Ridge MSE : {:.3f} / RMSE : {:.3f} / R2 : {:.3f}".format(ridge_test_mse, ridge_test_rmse, ridge_test_r2))
>>>LinearRegression MSE : 129848.080 / RMSE : 360.344 / R2 : -1769.645
Ridge MSE : 160.367 / RMSE : 12.664 / R2 : -1.187
alpha값 변화에 따른 ridge 회귀계수의 변화
fig, axs = plt.subplots(figsize=(18,6),nrows=1, ncols=5)
coeff_df = pd.DataFrame()
alphas = [0, 0.1, 1, 10, 100]
for pos, alpha in enumerate(alphas):
ridge = Ridge(alpha = alpha)
ridge.fit(X_data, y_target)
coeff = pd.Series(data = ridge.coef_, index = X_data.columns)
colname = 'alpha:'+str(alpha)
coeff_df[colname] = coeff
coeff = coeff.sort_values(ascending=False)
axs[pos].set_title(colname)
axs[pos].set_xlim(-3,6)
sns.barplot(x=coeff.values, y=coeff.index, ax=axs[pos])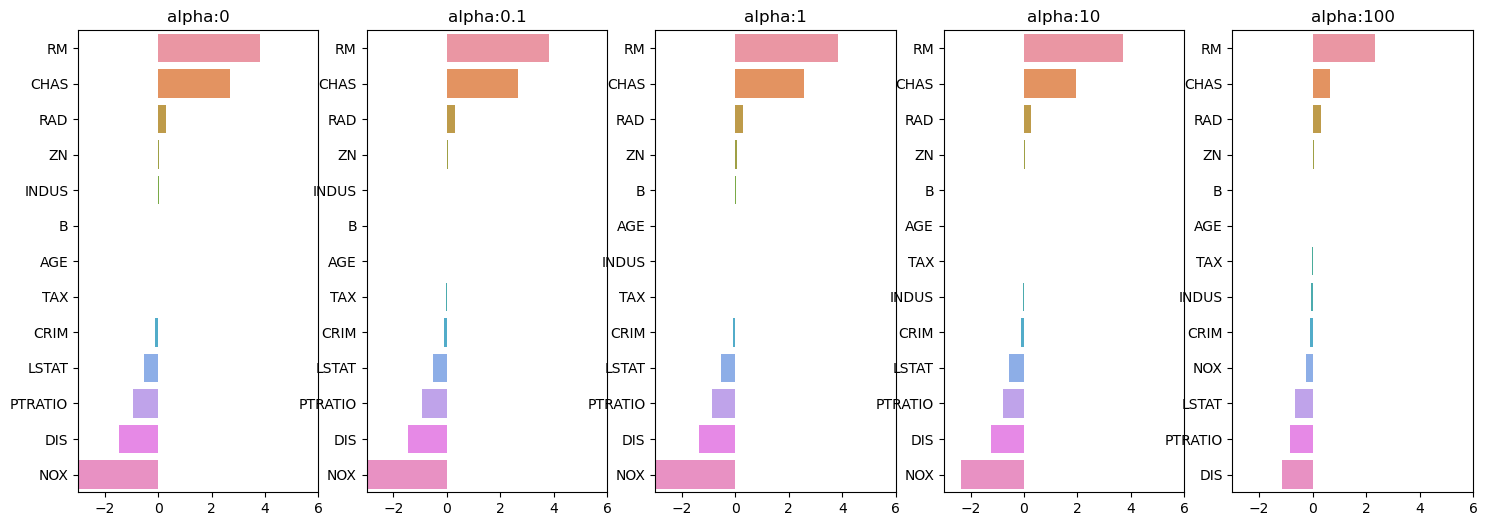
alpha값이 0->100으로 커질 수록 NOX 값은 줄어든다.
2. 라쏘회귀(L1): 회귀계수 0으로 만들 수 있음
Poly(X) + alpha=10
from sklearn.linear_model import Lasso
lr_lasso = Lasso(alpha=10).fit(X_train, y_train)
lasso_pred = lr_lasso.predict(X_test)
mse = mean_squared_error(y_test, lasso_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, lasso_pred)
print("MSE : {:.3f} / RMSE : {:.3f} / R2 : {:.3f}".format(mse, rmse, r2))
>>>MSE : 34.686 / RMSE : 5.889 / R2 : 0.527
Poly(O) + alpha=10
lr_lasso = Lasso(alpha=10).fit(X_train_3, y_train)
lasso_pred = lr_lasso.predict(X_test_3)
mse = mean_squared_error(y_test, lasso_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, lasso_pred)
print("MSE : {:.3f} / RMSE : {:.3f} / R2 : {:.3f}".format(mse, rmse, r2))
>>>MSE : 13.241 / RMSE : 3.639 / R2 : 0.819alpha값 변화에 따른 lasso 회귀계수의 변화
from sklearn.linear_model import Lasso
fig, axs = plt.subplots(figsize=(18,6),nrows=1, ncols=5)
coeff_df = pd.DataFrame()
alphas = [0.07, 0.1, 0.5, 1, 3]
for pos, alpha in enumerate(alphas):
lasso = Lasso(alpha = alpha)
lasso.fit(X_data, y_target)
coeff = pd.Series(data = lasso.coef_, index = X_data.columns)
colname = 'alpha:'+str(alpha)
coeff_df[colname] = coeff
coeff = coeff.sort_values(ascending=False)
axs[pos].set_title(colname)
axs[pos].set_xlim(-3,6)
sns.barplot(x=coeff.values, y=coeff.index, ax=axs[pos])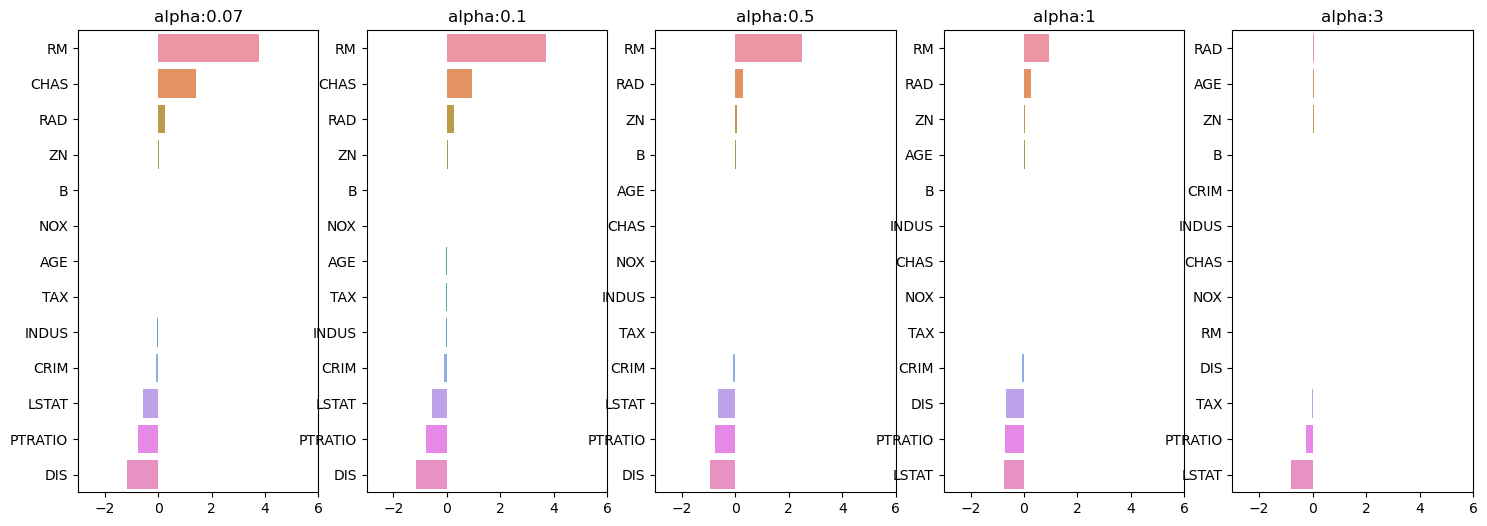
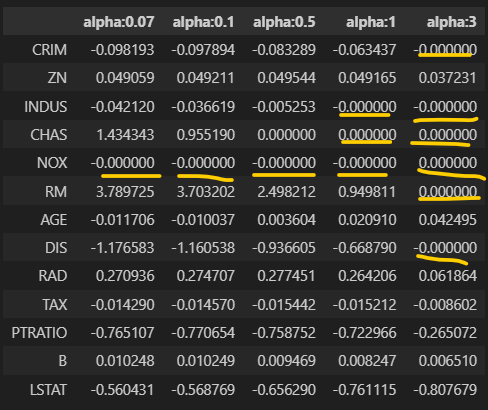
라쏘는 위의 데이터프레임과 같이 회귀계수 0인 피처들이 있다. 이러한 피처들은 회귀 식에서 제외되면서 피처 선택의 효과를 얻을 수 있다.
- Ridge보다 Lasso가 여기서는 성능이 더 좋다
- 피처들이 3차식일 때 (복잡해진 경우) Lasso가 더 나을 수 있다.
- 그러나 3차식으로 하는 경우는 특이케이스고, 일반케이스는 Ridge가 더 성능이 좋긴하다.
'#4. 기타 공부 > #4.2. 머신러닝' 카테고리의 다른 글
| [분류] 자전거대여 수요예측 (0) | 2023.09.05 |
|---|---|
| [분류] 신용카드 사기 검출 (0) | 2023.09.04 |
| [지도학습] 0. 회귀 (Regression) (0) | 2023.09.04 |
| [지도학습] 4-3. Boosting (부스팅) (0) | 2023.09.04 |
| [지도학습] 4-2. Bagging (배깅) (0) | 2023.09.04 |
'#4. 기타 공부/#4.2. 머신러닝' Related Articles
more

