

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 팔방이익구조
- 한장으로끝내는비즈니스모델100
- BM분석
- fundbox
- aarrr
- mysql설치 #mysql #mysqluser #mysqlworkbench
- 바로팜
- 퍼널분석
- 전환율
- allra
- 선정산서비스
- 인게이지먼트
- 활성화
- pmf
- activation
- 머신러닝
- 핀테크
- CAC
- 서말리포켓
- 코호트
- 올라
- 데이터분석
- 리텐션
- sklearn
- 비즈니스모델
- 역설구조
- model_selection
- retention
- 그로스해킹
- 셀프스토리지
- Today
- Total
데이터로그😎
[Hadoop] Hadoop, Spark 환경 세팅 본문
JAVA 환경변수 설정
대표적인 빅데이터 엔지니어링 시스템은 hadoop이다. hadoop은 JAVA를 기반으로 하기 때문에, 먼저 JAVA 환경변수를 설정해주겠다. 현재 Ubuntu 환경에서 진행 중이다.
1. ubuntu 계정 접속

2. JAVA 위치 확인
실제 java의 경로는 readlink 명령어로 확인 가능하다. 해당 명령을 실행한 결과, /usr/lib/jvm/java-11-openjdk-amd64/bin/java 라는 경로가 나왔다.

실제로 해당 디렉토리에 들어가보면 , /usr/lib/jvm/java-11-openjdk-amd64/bin 이라는 디렉토리 아래에 java라는 파일이 존재한다.

3. 환경변수에 JAVA 위치 등록
환경변수는 두가지 방법으로 등록 가능하다.
/etc/profile 파일, 그리고 .bashrc라는 파일에서 변경 가능하다. 두가지 방식의 차이점은 아래의 표와 같다.
지금은 ubuntu 계정의 환경변수만 변경할 것이기에 .bashrc를 사용하겠다.
| /etc/profiile | .bashrc | |
| 위치 | root 디렉토리 하에 있다. | 나의 계정의 홈 디렉토리에 있다. (/home/ubuntu/.bashrc) |
| 기능 | 모든 계정의 환경변수를 설정, 변경 | 내가 접속한 계정의 환경변수만 설정, 변경 |
3-1) .bashrc 파일 열기

3-2) .bashrc 파일에 java 위치 등록하기
readlink로 확인했던 java의 위치 中, JAVA_HOME은 java의 home directory을 기재하고, PATH에는 홈 디렉토리 안의 bin 디렉토리를 기재한다. 이를 모두 입력한 후 저장하고 나오기~ 이로써 java의 환경을 등록 완료했다.

HDFS 환경변수 설정
가상환경 설정
먼저 spark를 설치, 사용할 가상환경을 생성하려 한다.
0. 가상환경 사용 이유
- 가상환경(Virtual Environment)을 사용하는 이유는 프로젝트 간 충돌을 예방하기 위해서다.
- 즉, 가상환경은 각 프로젝트에 필요한 라이브러리 등을 독립된 공간에 위치시킴으로써 일일이 버전을 확인하고 관리함에 있어 발생하는 불편함을 해소시킨다.
- 출처: https://velog.io/@jewon119/TIL36.-Miniconda-%EC%84%A4%EC%B9%98-%EB%B0%8F-%EA%B0%80%EC%83%81%ED%99%98%EA%B2%BD-%EC%A7%84%EC%9E%85
1. 가상환경 리스트 확인하기
1. 가상환경 리스트 확인하기
나는 이미 airflow-env, spark-env를 만들어놨지만, 다시 한 번 생성해보겠다.
이번엔 spark-hdfs-env 를 생성해보자.

2. 가상환경 생성 & 활성화 하기
2-1) spark-hdfs-env 생성
conda create -n 명령어로 새로운 가상환경을 생성할 수 있다. 명령어를 실행하면 가상환경의 위치와 함께 설치되는 패키지 정보들이 나온다. 가상환경은 /home/ubuntu/miniconda3/envs/에 위치한다네.

2-2) 가상환경 activate
가상환경을 만들었으니 이제 활성화 시켜보겠다. conda activte 명령어를 사용하여 활성화 할 수 있다. 활성화 한 후 (base) 부분이 (spark-hdfs-env)로 변경된 것을 볼 수 있다.

miniconda3 설치
0. conda 란?
- Conda는 오픈 소스 패키지 및 환경 관리 시스템으로, Python 및 다른 프로그래밍 언어의 패키지 설치, 업데이트, 관리를 쉽게 할 수 있게 해주는 도구
- Conda 저장소에는 Python 라이브러리뿐만 아니라 데이터 과학, 과학적 계산, 기계 학습, 딥 러닝, 시각화, 웹 개발 등 다양한 분야에서 사용되는 수많은 패키지가 포함되어 있습니다.
- numpy, pandas, scikit-learn, pytorch, jupyter 등의 라이브러리 포함
1. 설치하기
which python으로 python의 위치를 확인하는 이유는 가상환경 내에 python이 설치되어 있어야 진행이 되기 때문이다. 확인 결과, /home/ubuntu/miniconda3/envs/spark-hdfs-env/bin/python 이 나오면 된다.
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
conda activate spark-hdfs-env # 가상환경 activate
which python # python 경로 확인
Hadoop 세팅하기
1. 설치파일 받아오기 (wget)
# 1) 하둡 처음에 받아옴
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.5/hadoop-3.3.5.tar.gz
# 2) 압축 해제(xvfz)
tar xvfz hadoop-3.3.5.tar.gz
하둡 압축 해제까지 완료하면 home directory에 hadoop-3.3.5 디렉토리가 생긴 것을 볼 수 있다.
2. 환경변수에 hadoop 경로 등록
1) .bashrc 파일 열기
vim ~/.bashrc
2) hadoop 경로 등록 후 저장
이전에 등록했던 JAVA PATH 밑에 HADOOP PATH도 등록하면 된다.
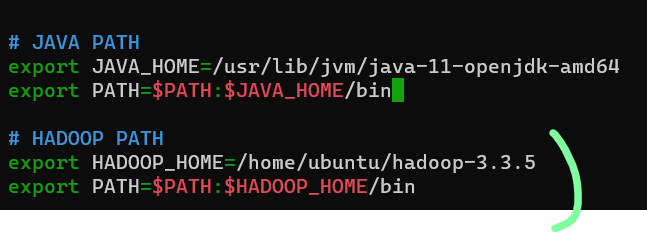
3) source ~/.bashrc 로 변경 내용 적용하기
source ~/.bashrc
4) master - worker 사이에 key 생성
SSH 키 생성 및 설정은 Hadoop 클러스터에서 서로간에 안전하게 통신하고 서비스 간에 노드 간 인증을 수행하기 위해 필요하다.
4-1) key 생성
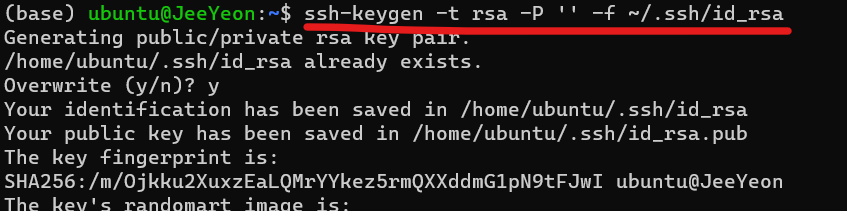
4-2) SSH 공개 키를 authorized_keys 파일에 추가 & 권한 설정 (chmod)
chmod 0600 : 해당 파일이 소유자만 읽고 쓸 수 있도록 하는 것으로, 보안상의 이유로 필요한 설정

3. hadoop 설정파일 변경
Hadoop은 다양한 설정 파일을 사용하여 클러스터를 구성하고 제어한다. 주요한 Hadoop 설정 파일들은 다음과 같다.
| 설정 파일 | 설명 |
| core-site.xml | - Hadoop 클러스터의 기본 구성을 정의합니다. - 주로 Hadoop 파일 시스템(HDFS)과 관련된 설정을 담고 있습니다. |
| hdfs-site.xml | - Hadoop 분산 파일 시스템(HDFS)에 대한 구성을 정의합니다. - 블록 크기, 복제 팩터 등과 같은 HDFS의 동작에 관한 설정이 포함됩니다. |
| mapred-site.xml: | - MapReduce 작업 프레임워크에 대한 설정을 정의합니다. - JobTracker와 TaskTracker의 위치, 리소스 관리자 등과 관련된 설정이 여기에 포함됩니다. |
| yarn-site.xml | - YARN (Yet Another Resource Negotiator)에 대한 설정을 포함합니다. - 클러스터 리소스 관리와 작업 스케줄링 등과 관련된 설정이 있습니다. |
1) core-site.xml 파일 설정 ( 하둡 master가 시작될 ip,port를 설정)
- 파일 열기
vim $HADOOP_HOME/etc/hadoop/core-site.xml - core-site.xml 파일 내에 아래의 내용을 추가
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
2) hdfs-site.xml ( 데이터 노드 설정 )
2-1) dfs/name과 dfs/data 디렉토리 생성
하둡의 name node의 메타 데이터는 dfs/name 디렉토리에 저장되고, 데이터노드의 블록 데이터는 dfs/data 디렉토리에 저장된다.
mkdir -p $HADOOP_HOME/dfs/name
mkdir -p $HADOOP_HOME/dfs/data
2-2) hdfs-site.xml 파일 설정
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/ubuntu/hadoop-3.3.5/dfs/name</value>
</property>
<property>
<name>dfs.datanode.name.dir</name>
<value>/home/ubuntu/hadoop-3.3.5/dfs/data</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>localhost:9870</value>
</property>
</configuration>| dfs.replication | - 파일 깨짐을 방지하기 위해 복제 인수를 설정한다. - 만약 dfs.replication의 value가 2라면 각 노드에 파일을 2개씩 저장해놓는다. - 장애대응을 위해서 복제 파일을 저장하며, 주로 3,5,7 홀수, 소수단위로 설정한다. |
| dfs.namenode.name.dir | - namenode = master - master의 메타데이터가 들어가는 곳 |
| dfs.datanode.name.idr | - 실제 데이터가 저장되는 디렉토리 - 파일 조각들이 들어가는 곳 |
3) yarn-site.xml (클러스터 리소스 관리 및 스케쥴링 설정)
아래의 내용 추가.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP>
</property>
<!-- Site specific YARN configuration properties -->
</configuration>
4) mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP>
</property>
</configuration>
4. hadoop 실행
1) 포맷: 최초세팅이다. 단 한번만 실행합니다!
hdfs namenode -format
2) namenode 실행

3) yarn 실행

4) 켜져있는 노드 확인(jps)
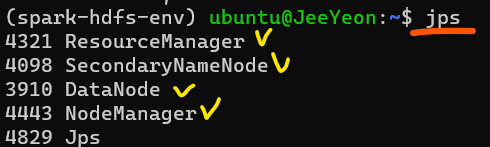
Spark 세팅하기
1. 설치파일 받아오기 (wget)
wget https://dlcdn.apache.org/spark/spark-3.2.4/spark-3.2.4-bin-hadoop3.2.tgz
tar xvfz spark-3.2.4-bin-hadoop3.2.tgz
2. 파일 이름 변경
mv spark-3.2.4-bin-hadoop3.2 spark-3.2.4
3. 환경변수에 Spark 경로 등록
1) .bashrc 파일 열기
vim ~/.bashrc
2) Spark 경로 등록 후 저장
이전에 등록했던 JAVA PATH 밑에 HADOOP PATH도 등록하면 된다.
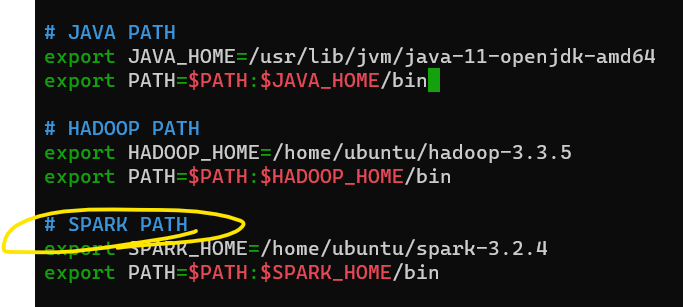
3) source ~/.bashrc 로 변경 내용 적용하기
source ~/.bashrc
4) 가상환경 설정
4-1) 가상환경.sh 파일열기 (각자 생성했던 가상환경을 spark-hdfs-env 부분에 적는다.)
vim $SPARK_HOME/conf/spark-hdfs-env.sh
4-2) pyspark 경로 등록
export PYSPARK_PYTHON=/home/ubuntu/miniconda3/envs/spark_env/bin/python
4-3) pyspark 설치 및 실행
pip install pyspark==3.2.4
# 설치 끝나면 pyspark 입력 --> pyspark 실행
pyspark
pyspark 입력하여 실행 후 아래와 같은 이미지 나오면 성공~

Jupyter notebook 설치
1. 설치
conda activate spark-hdfs-env # 가상환경 실행
conda install notebook # notebook 다운
2. jupyter notbook 비밀번호 설정
ipython 실행하고 패스워드를 설정하면 내가 설정한 패스워드가 암호화 되어 나오게 된다. 'argon2~~' 이런식으로.
이 암호화 된 패스워드를 잘 기억해놓아야 한다! (notepad에 저장해놓기)
ipython
---------------------------------------
pip install notebook
from jupyter_server.auth import passwd
passwd()
--------------------------
3. jupyter notbook 설정
1) jupyter 설정 파일 생성
jupyter notebook --generate-config
2) config 파일 열기
sudo nano /home/ubuntu/.jupyter/jupyter_notebook_config.py
3) jupyter_notebook_config.py 에 아래 내용 추가하기
c = get_config()
c.NotebookApp.password = u'argon2~~로 암호화 된 비번 넣기'
c.NotebookApp.ip = '172.~~' # ip
c.NotebookApp.notebook_dir = '/home/ubuntu/working/spark-example' # notebook이 저장될 폴더
4. jupyter notbook 실행
jupyter notebook --allow-root
web brower에 http://ip:8888/tree 를 입력해서 들어가라~
이때 ip는 jupyter_notebook_config.py에 c.NotebookApp.ip 에 입력했던 ip이다.
'#4. 기타 공부 > #4.1. Data Engineering' 카테고리의 다른 글
| [Hadoop] HDFS(Hadoop Distributed File System) (0) | 2024.01.22 |
|---|---|
| [Hadoop] 빅데이터 아키텍처 (0) | 2024.01.21 |
| [Linux] 8. Internet, Network, Server ② SSH, Port (0) | 2024.01.18 |
| [Linux] 8. Internet, Network, Server ① (0) | 2024.01.17 |
| [Linux] 7. 권한 (permission) (0) | 2024.01.16 |



