

Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- 핀테크
- mysql설치 #mysql #mysqluser #mysqlworkbench
- 퍼널분석
- CAC
- activation
- 서말리포켓
- 그로스해킹
- 올라
- allra
- 바로팜
- 선정산서비스
- 머신러닝
- 데이터분석
- BM분석
- 활성화
- 전환율
- retention
- 코호트
- 리텐션
- 한장으로끝내는비즈니스모델100
- pmf
- model_selection
- 역설구조
- 셀프스토리지
- aarrr
- 비즈니스모델
- 인게이지먼트
- fundbox
- 팔방이익구조
- sklearn
Archives
- Today
- Total
데이터로그😎
[비지도 학습] 군집: Meanshift vs DBSCAN 본문
비모수 추정 방법 (Non-parametric Clustering)
| Meanshift | DBSCAN | |
| 군집 개수 | 사전 설정 X | |
| 기반 | 밀도 기반 | |
| 언제 사용? | 데이터가 밀도가 높은 영역에 모여있는 경우 | 높은 차원 데이터에 대해 |
| 특징 |
|
|
| 파라미터 |
|
|
| 메소드 |
|
|
| 속성 |
|
|
MeanShift
- 데이터 분포도(밀도)를 계산하여 높은 쪽으로 군집 중심점이 이동
- 데이터 밀도가 높은 곳으로 이동하기 위해 주변 데이터와의 거리 값을 KDE(커널 밀도추정) 함수 값으로 입력함 -> 그 반환 값을 현재 위치에서 업데이트 하면서 이동하는 방식.
- KDE(커널 밀도 추정)는 확률 밀도 함수(Probability Density Function, PDF)를 추정하는 비모수 통계 기법.
- KDE는 데이터 포인트 주변에 작은 커널(일종의 함수)을 배치하고 이 커널을 사용하여 각 데이터 포인트 주변의 밀도를 추정합니다. 이렇게 하면 데이터 분포의 전체적인 모양을 근사화하고 부드러운 확률 밀도 함수를 얻을 수 있음. 커널 함수는 일반적으로 가우시안 함수(정규 분포)를 사용하는 것이 일반적이지만, 다른 커널 함수도 사용할 수 있음.
데이터 준비
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.cluster import MeanShift
X,y = make_blobs(n_samples=200, n_features=2, centers=3, cluster_std=0.7,
random_state=0)
meanshift= MeanShift(bandwidth=0.8)
cluster_labels = meanshift.fit_predict(X)
np.unique(cluster_labels) # 지나친 세분화 군집
>>>array([0, 1, 2, 3, 4, 5], dtype=int64)estimate_bandwidth()로 최적의 대역폭 찾기
from sklearn.cluster import estimate_bandwidth
bandwidth = estimate_bandwidth(X)
bandwidth # 최적의 bandwidth(대역폭)
>>1.8158484154517098estimate_bandwidth를 MeanShift에 적용하기
import pandas as pd
clusterDF = pd.DataFrame(X, colums=['ft1','ft2'])
clusterDF['target']= y
# X데이터를 meanshift 군집화
best_bandwidth = estimate_bandwidth(X)
meanshift = MeanShift(bandwidth = best_bandwidth)
cluster_labels = meanshift.fit_predict(X)
시각화
import matplotlib.pyplot as plt
%matplotlib inline
clusterDF['meanshift_label'] = cluster_labels
unique_labels = np.unique(cluster_labels)
centers = meanshift.cluster_centers_
for label in unique_labels:
label_cluster = clusterDF[clusterDF['meanshift_label']==label]
center_x_y = centers[label]
plt.scatter(x=label_cluster['ftr1'], y=label_cluster['ftr2'])
plt.scatter(x= center_x_y[0], y=center_x_y[1], s=200, color='gray',alpha=0.9)
plt.scatter(x=center_x_y[0], y=center_x_y[1], s=70, color='k',
marker = '$%d$' % label)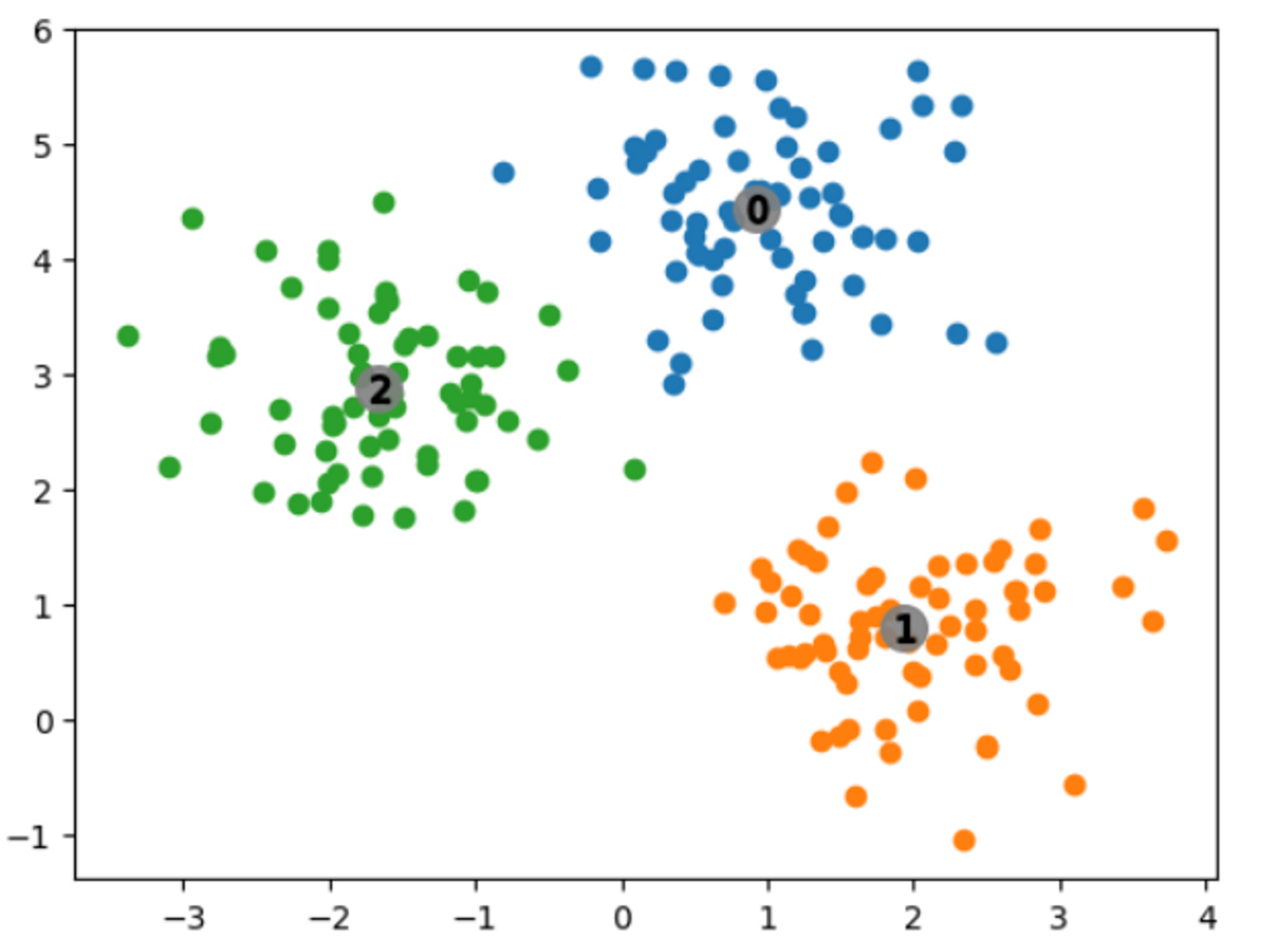
결과 확인 (groupby)
clusterDF.groupby('target')['meanshift_label'].value_counts()
>>>>>>>>>>>>>>>>>>>>>
target meanshift_label
0 0 67
1 1 67
2 2 66
Name: meanshift_label, dtype: int64
DBSCAN
데이터 준비
from sklearn.cluster import DBSCAN
from sklearn.datasets import load_iris
import pandas as pd
iris= load_iris()
irisDF = pd.DataFrame(iris.data, columns = iris.feature_names)
irisDF
DBSCAN
dbscan = DBSCAN(eps=0.6, min_samples = 8, metric='euclidean')
dbscan_labels = dbscan.fit_predict(iris.data)
irisDF['dbscan_cluster'] = dbscan_labels
irisDF['target'] = iris.target]
irisDF.groupby(['target','dbscan_cluster']).count()['sepal length (cm)']
>>>>
target dbscan_cluster
0 -1 1
0 49
1 -1 4
1 46
2 -1 8
1 42
Name: sepal length (cm), dtype: int64
시각화 위해 PCA(4→2차원) 실행
from sklearn.decomposition import PCA
pca = PCA(n_components =2, random_state=0)
pca_transformed = pca.fit_transform(iris.data)
irisDF['ftr1'] = pca_transformed[:,0]
irisDF['ftr2'] = pca_transformed[:,1]
np.unique(irisDF['dbscan_cluster'])
>>>array([-1, 0, 1], dtype=int64)
#-1은 노이즈
시각화
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
plt.scatter(x=irisDF[irisDF['dbscan_cluster'] ==0]['ftr1'], y=irisDF[irisDF['dbscan_cluster'] ==0]['ftr2'])
plt.scatter(x=irisDF[irisDF['dbscan_cluster'] ==1]['ftr1'], y=irisDF[irisDF['dbscan_cluster'] ==1]['ftr2'])
plt.scatter(x=irisDF[irisDF['dbscan_cluster'] ==-1]['ftr1'], y=irisDF[irisDF['dbscan_cluster'] ==-1]['ftr2'],marker = '*')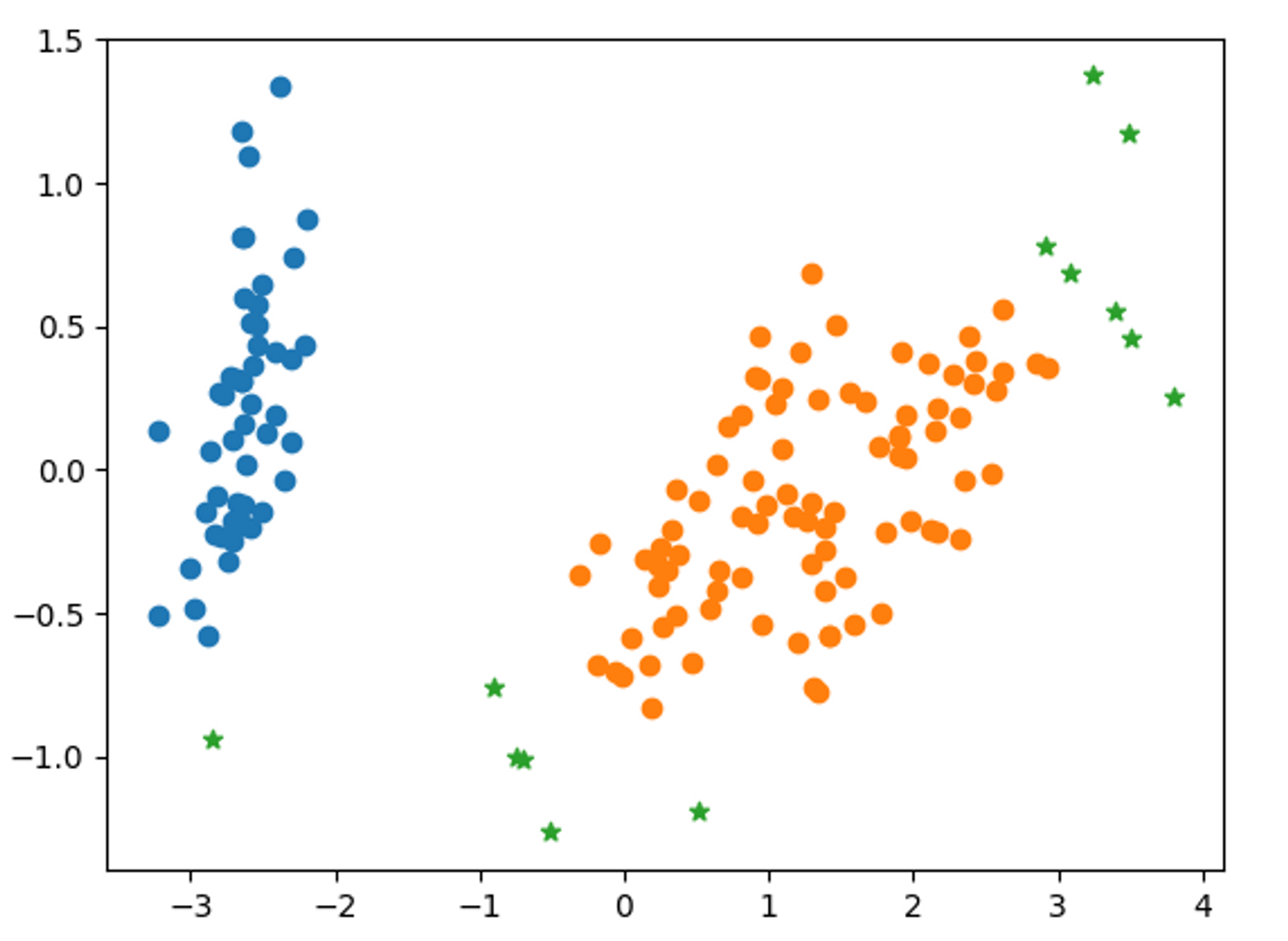
'#4. 기타 공부 > #4.2. 머신러닝' 카테고리의 다른 글
| [비지도 학습] 군집 평가 (0) | 2023.09.05 |
|---|---|
| [비지도 학습] 군집: KMeans, GMM (0) | 2023.09.05 |
| [비지도 학습] 군집 (clustering) (0) | 2023.09.05 |
| [차원축소] SVD (Singular Value Decomposition) (0) | 2023.09.05 |
| [차원축소] LDA (Linear Descriminant Analysis) (0) | 2023.09.05 |
'#4. 기타 공부/#4.2. 머신러닝' Related Articles
more

