
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 인게이지먼트
- 그로스해킹
- 머신러닝
- 팔방이익구조
- 활성화
- retention
- BM분석
- 리텐션
- 올라
- 선정산서비스
- 코호트
- 바로팜
- 한장으로끝내는비즈니스모델100
- 서말리포켓
- 핀테크
- 셀프스토리지
- model_selection
- 비즈니스모델
- allra
- fundbox
- aarrr
- 역설구조
- 데이터분석
- 전환율
- sklearn
- mysql설치 #mysql #mysqluser #mysqlworkbench
- 퍼널분석
- pmf
- CAC
- activation
- Today
- Total
데이터로그😎
[DNN] 02. DNN 설계 단계 - ① 레이어 설계 본문
✔️설계 단계
DNN (Deep Neural Network)를 설계할 때는 크게 아래의 네가지 단계를 거친다.
레이어 설계 (입력층, 은닉층, 출력층) → 손실함수 선정 → 최적화 방식 선정 →훈련.
① 레이어 설계
- 입력층: Feature 개수만큼 설계
- 은닉층: 필요에 맞게
- 출력층: 클래스의 개수에 맞게 설정
- 활성화 함수
- 로지스틱 (출력층 뉴런 1개일 때)
- 소프트 맥스 (출력층 뉴런이 2개 이상일 때)
② Loss 선정 (손실함수)
- CCE (Categorical Cross Entrophy)
- Categorial Cross Entropy
- target이 원핫인코딩이 되어있는 경우
- [0,1,0,…]
- Sparse Categorical Cross Entropy
- target이 Label Encoding이 되어있는 경우
- [0,3,1,2,5,..]
- Categorial Cross Entropy
③ Optimizer (최적화)
- Adam
- RMSprop
- SGD
④ 훈련
- x, y선정 (*필수)
- 배치사이즈 (*필수) → 논문에서는 32~64가 최적이라 함. 128개 이상 x
- 에폭 (*필수)
- 셔플 여부 (반 필수)
- 검증 set 설정 (반 필수)
먼저 1단계 "레이어 설계" 中 은닉층의 설계에 대해 알아보겠다.
✔️은닉층 설계
① 가중치

은닉층의 행렬 구조에 대해서 알아야 한다.
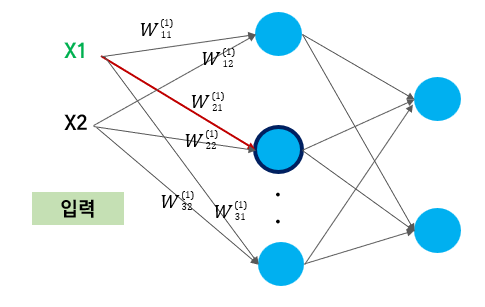
가중치에 번호를 기재하는 법을 알아보자. W의 우측 상단에는 가중치가 향하고 있는 "층" 을 기재하고,
우측 하단에는 가중치가 출발하는 입력값, 도착하는 뉴런의 순서를 기재하면 된다.
예를 들어보면, 위의 사진에서 빨간 화살표로 표시된 가중치를 어떻게 기재하는지 알아보자.
빨간 화살표는 "첫번째 층" 으로 향하고 있고, X1이라는 첫번째 입력값에서 출발하여 첫번째 층의 "두번째 뉴런"으로 향하고 있다.
따라서 기재 방식은 아래와 같이 되는 것이다. 모두가 이해 했길 바라며...
② 가중치 행렬
이제 1층 (첫번째 layer)의 가중치 행렬을 알아보겠다.
위의 설명대로라면 첫번째 층으로 향하는 각 가중치는 아래와 같다.
그럼 1층의 가중치 행렬은 아래와 같다. 각 행은 각 뉴런으로 향하는 가중치들을 의미한다. 화살표를 의미한다고 생각해도 된다.
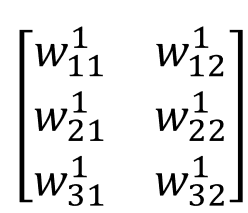
그럼 1층의 결과물을 알아볼까? 이전에 언급한 것처럼, 각 층의 결과물은 아래 두단계를 거쳐 최종적인 결과물이 나오게 된다.
- Z = W*x + b
- Activation function에 Z를 넣은 a(Z)가 최종 결과물
최종 결과물인 A(1)은 아래와 같다!
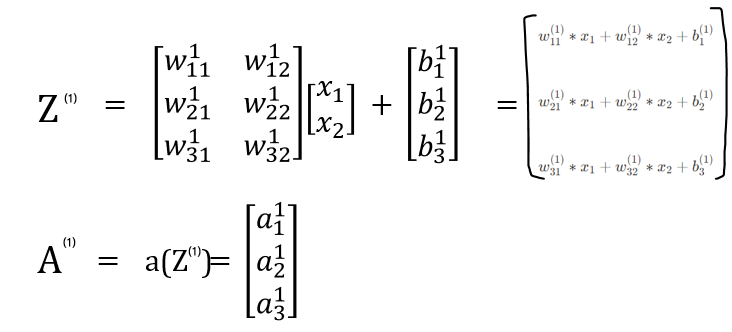
이 A(1)은 layer1의 결과물이다.
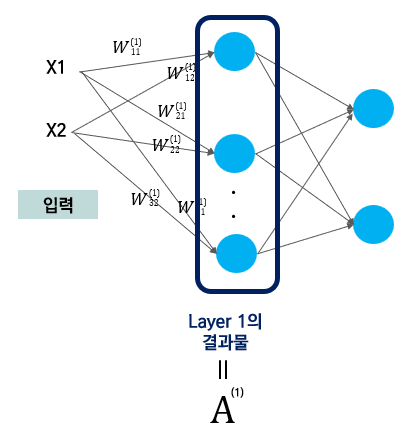
하지만, 아직 끝나지 않았다.. Layer2까지 있으니까..^^*
Layer 2 계산은 아주 빠르게 끝내보겠다.
Z(2) = W(2) * A(1) + b(2)이고, Z(2)를 다시 activation function에 넣은 결과는 a(Z(2))이다!
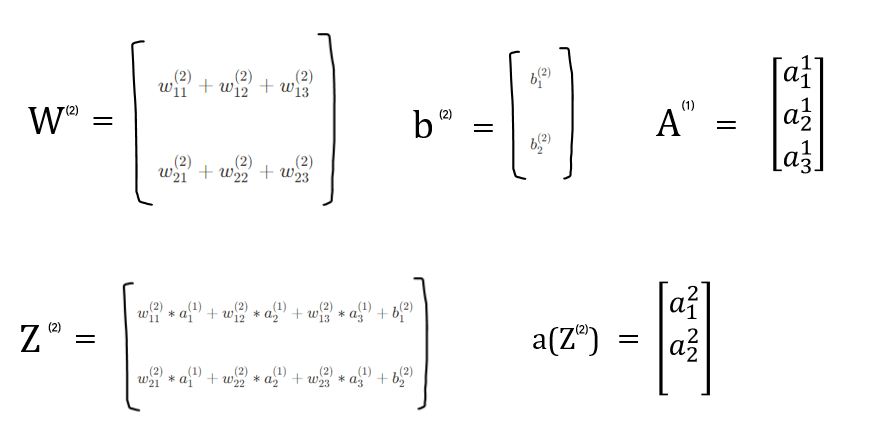
딥러닝은 이렇게 선형조합→활성화함수→선형조합→활성화함수→ 선형조합→활성화함수....를 계속 반복하여 값을 찾는 것이다!
✔️출력층 설계
출력층의 설계는 모델이 회귀인지 분류인지에 따라서 다르다.
① 회귀
- 출력층 뉴런 개수: 회귀니까 결과값, 즉 y^(y hat)이 1개만 나오면 되기 때문에, 출력층의 뉴런을 1개만 씀
- 회귀의 활성화 함수: 항등함수
- 항등함수(identity function) ⇒ f(x) = x
- 선형으로 예측을 했으면 그 결과에 변화를 줄 필요는 없기 때문에 활성화 함수를 항등함수로 씀
- 회귀엔 비선형성이 부여되면 안됨.
- 그런데 딥러닝의 모든 연산은 "선형조합→활성화 함수"가 계속 반복되기 때문에, 굳이 선형 조합 후에 활성화 함수를 써서 선형 결과를 바꿀 필요는 없지만, 형식을 맞춰주기 위해 항등함수를 쓴다.
- why? 연봉측정할때 결론이 4000만원이라고 나왔으면 그거 그냥 쓰면 되는데 여기다가 비선형성을 부여햘 필요가 없음
② 분류
- 이진분류: yes or no
- 출력층 뉴런 개수: 1
- 활성화 함수: 로지스틱 함수 (시그모이드)
- 선형 결과에 비선형성을 부여하기 위해 사용
- 다중 분류
- 출력층 뉴런 개수: 분류할 클래스의 개수만큼 출력층에 뉴런을 설정
- ex) iris: 3개(setosa, verginica, veronica)
- ex) 암: 2개 (tumor, cancer)
- ex) 강아지, 고양이 분류: 분류할 개수가 2개니까 출력층에 2개의 뉴런 설정
- ex) 0~9까지 숫자 분류: 분류할 개수가 10개니까 출력층에 10개의 뉴런 설정
- 활성화 함수: softmax
- 각 클래스에 속할 확률
- 결과값의 전체 합이 항상 1
- 출력층 뉴런 개수: 분류할 클래스의 개수만큼 출력층에 뉴런을 설정
'#4. 기타 공부 > #4.3. 딥러닝' 카테고리의 다른 글
| [CNN] FCL vs CNN (0) | 2023.12.02 |
|---|---|
| [DNN] DNN 설계 단계 - ② 손실함수, ③ 최적화 (1) | 2023.12.02 |
| [DNN] 01. DNN 기본 용어 (0) | 2023.11.28 |
| [MLP] 03. 활성화 함수 (Activation Function) (1) | 2023.11.28 |
| [MLP] 02. 단층(SLP), 다층 퍼셉트론 (MLP) (1) | 2023.11.28 |


