

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 퍼널분석
- model_selection
- 팔방이익구조
- 셀프스토리지
- pmf
- 비즈니스모델
- 핀테크
- CAC
- 올라
- fundbox
- 코호트
- aarrr
- 그로스해킹
- sklearn
- BM분석
- 서말리포켓
- allra
- 리텐션
- 인게이지먼트
- 역설구조
- 선정산서비스
- 데이터분석
- 바로팜
- 머신러닝
- mysql설치 #mysql #mysqluser #mysqlworkbench
- retention
- activation
- 전환율
- 활성화
- 한장으로끝내는비즈니스모델100
- Today
- Total
데이터로그😎
[DNN] DNN 설계 단계 - ② 손실함수, ③ 최적화 본문
[DNN] 02. DNN 설계 단계 - ① 레이어 설계
✔️설계 단계 DNN (Deep Neural Network)를 설계할 때는 크게 아래의 네가지 단계를 거친다. 레이어 설계 (입력층, 은닉층, 출력층) → 손실함수 선정 → 최적화 방식 선정 →훈련. ① 레이어 설계 입력
fine-1004.tistory.com
✔️손실함수 (Loss Function)
- 손실함수는 기계학습, 딥러닝에서 모델의 성능을 측정하는 데 사용되는 함수
- 모델의 "실제값(y) - 예측값(y^)" 을 나타내며, 손실함수의 값이 낮을 수록 모델의 성능이 좋다고 평가된다.
- 머신러닝의 학습 과정은 이 손실함수를 최소화하는 방향으로 진행된다.
- 손실함수는 해결하려는 문제에 따라 달라진다. (회귀, 분류, 클러스터링..)
- 종류: 평균 제곱 오차(Mean Squared Error, MSE), 교차 엔트로피(Cross-Entrophy Error) 등
- MSE는 주로 회귀, CEE는 분류 문제에 자주 사용된다.
① 평균 제곱 오차 (Mean Squared Erorr, MSE)

- x(i) = 실제값, x(i) bar =예측값
- m: 출력 차원
- 예) MNIST에서 m= width * height * channels = 28 * 28 *1 = 784
- MSE는 오차의 제곱을 사용하기 때문에 큰 오차에 대해 더 큰 패널티를 부여함.
② 교차 엔트로피 (Cross Entrophy Error)
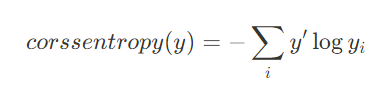
- 각 데이터 포인트에서 예측된 클래스의 확률 분포와 실제 클래스의 확률분포 사이의 교차 엔트로피를 계산한 후, 이를 모든 데이터 포인트에 대해 평균을 낸 값.
- 교차 엔트로피 값이 작을 수록 정확한 값을 냄.
- CEE는 두 분포 사이의 차이를 측정하기 때문에, 모델의 예측이 실제와 얼마나 일치하는지를 평가한다.
✔️최적화 (Optimizer)
- 최적화란 손실을 최소화할 수 있는 모델 파라미터(W,b)의 갱신 방법.
- 자세한 설명은..위키닥스를 참고하겠다..https://wikidocs.net/165136
C_06. Optimization Algorithms
딥 러닝에는 현재 순간에 모델이 얼마나 저조한 성능을 발휘하는지 알려주는 손실 개념이 있습니다. 이제 우리는 이 손실을 사용하여 네트워크가 더 잘 수행되도록 훈련해야 합니다. 기…
wikidocs.net
최적화 알고리즘 中, 배치 경사 하강법(Batch Gradient Descent , BGD) 이라는 것이 존재한다.
🔹 배치 경사 하강법(Batch Gradient Descent , BGD)
Batch 란 축적된 과거의 데이터를 의미한다. MySQL, CSV, 파일 시스템 등을 통해 과거의 데이터를 보관할 수 있다.
만약 batch data가 60,000장의 이미지 데이터라고 가정하자. 이 때, 전체 훈련 데이터를 통해 경사 하강법을 실행하는 것이 BGD이다.
그런데 만약 데이터가 6만장이고, 이를 한 번에 훈련한다면 힘들 것이다. 과부하가 걸릴 수도?
그래서 mini- batch라는 개념이 나왔다.
🔹 미니배치 경사 하강법(Mini-batch Gradient Descent ,MGD)
훈련 시 전체 데이터인 6만장의 이미지를 다 사용해야 할 것 같지만, *통계적인 이유로 그보다 작은 Mini- batch를 사용해도 된다.
여기서 *통계적인 이유 중 하나는 '중심 극한의 정리' 이다. 중심 극한의 정리란 '독립적이고 동일한 확률 분포를 가진 변수들의 합은 표본 크기가 충분하면 정규분포에 근사하다' 는 것이다. 이러한 통계적인 이유로 인해 미니배치는 전체 데이터셋의 통계적인 특성을 반영하여 모집단을 대표할 수 있다고 가정하며, MGD는 전체 데이터를 미니배치 단위로 나누어 모델을 반복적으로 훈련다.
'#4. 기타 공부 > #4.3. 딥러닝' 카테고리의 다른 글
| [FCL] Full Connected Layer (1) | 2023.12.03 |
|---|---|
| [CNN] FCL vs CNN (0) | 2023.12.02 |
| [DNN] 02. DNN 설계 단계 - ① 레이어 설계 (0) | 2023.11.28 |
| [DNN] 01. DNN 기본 용어 (0) | 2023.11.28 |
| [MLP] 03. 활성화 함수 (Activation Function) (1) | 2023.11.28 |


