

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 팔방이익구조
- 데이터분석
- 서말리포켓
- 활성화
- 그로스해킹
- 리텐션
- 코호트
- 비즈니스모델
- sklearn
- retention
- 선정산서비스
- pmf
- 전환율
- CAC
- model_selection
- activation
- 인게이지먼트
- 셀프스토리지
- 머신러닝
- allra
- 바로팜
- mysql설치 #mysql #mysqluser #mysqlworkbench
- BM분석
- 역설구조
- 퍼널분석
- 올라
- 한장으로끝내는비즈니스모델100
- 핀테크
- fundbox
- aarrr
- Today
- Total
목록#4. 기타 공부/#4.1. Data Engineering (23)
데이터로그😎
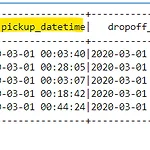 [Spark] Spark SQL에서 날짜 형식 중 년, 월, 일 따로 추출하는 법!
[Spark] Spark SQL에서 날짜 형식 중 년, 월, 일 따로 추출하는 법!
spark3.0이 도입되면서 약간 룰이 달라졌다. 지금부터 도입 이전, 후에 어떻게 달라졌는지 알아보겠다. Spark 3.0 이전 from pyspark.sql import SparkSession spark = SparkSession.builder.appName('trip').getOrCreate() filepath = '/home/ubuntu/working/spark-example/data/fhvhv_tripdata_2020-03.csv' taxi_df = spark.read.csv(f'file:///{filepath}', inferSchema=True, header= True) taxi_df.show(5) 한 번 데이터 프레임의 데이터 형식을 알아볼까? taxi_df.printSchema() ####..
 [Spark] Spark Machine-Learning
[Spark] Spark Machine-Learning
데이터 생성 from sklearn.datasets import load_iris import pandas as pd import numpy as np # iris datasets 로딩 iris = load_iris() iris_data = iris.data # feature iris_label = iris.target # label iris_columns = ["sepal_length", "sepal_width", "petal_length", "petal_width"] iris_pdf = pd.DataFrame(iris_data, columns=iris_columns) iris_pdf['target'] = iris_label iris_pdf spark ml에서도 사용할 수 있도록 iris_pdf는 cs..
데이터 불러오기 from pyspark.sql import SparkSession # spark session 생성 spark = SparkSession.builder.master('local').appName('spark-sql').getOrCreate() movies = [ (1, "어벤져스", "마블", 2012, 4, 26), (2, "슈퍼맨", "DC", 2013, 6, 13), (3, "배트맨", "DC", 2008, 8, 6), (4, "겨울왕국", "디즈니", 2014, 1, 16), (5, "아이언맨", "마블", 2008, 4, 30) ] # RDD movie_schema = ["id", "name", "company", "year", "month", "day"] attendances ..
1. Resilient Distributed Dataset(RDD) 스파크에서 사용하는 데이터의 최소단위. 판다스에 넘파이가 있다면 spark sql, df에는 rdd가 있다! # 특징 RDD = 스파크의 핵심 데이터 모델 cluster에 있는 worker 의 메모리 안쪽에 RDD가 위치함. worker들의 메모리에 RDD가 쪼개져서 위치함. 각 RDD들은 서로 연관이 있음. 변경이 불가. Inplace 불가. 작업을 할 때마다 새로운 RDD를 계속 만들게 됨. 데이터 추상화 여러군데에 쪼개져있는 파일을 마치 하나의 파일처럼 사용할 수 있도록 추상화 함. 파일을 하나하나 신경써서 일일이 불러오는게 아니고 tool이 알아서 파악해서 불러옴. 100PB파일을 여러개의 HDFS에 분산되어 저장 HDFS에 분산..
 분산 병렬 처리 시스템 (MPP, DFS)
분산 병렬 처리 시스템 (MPP, DFS)
MPP(Massively Parallel Processing) MPP 구조 - 각각 다른 Machine & 각각 다른 DB - 여러개의 컴퓨터 특징 - 대용량 병렬 처리 개념의 등장 → 슈퍼컴퓨터(기상청,..) - 컴터 한대한대씩 거대한 데이터베이스를 하나씩 담당해서 따로따로 병렬로 처리 처리 순서 1. 중앙 컴퓨터가 명령 내림(Communications Facility) 2. 명령받은 머신들은 데이터를 분할해서 병렬처리한다. 단점 - 비싸다. - 데이터끼리 조인 필요할때는? 필연적으로 컴터들끼리의 네트워크 통신 필요.. - 한 컴터가 담당하는 데이터가 만약 2.5TB라면…. 이걸 컴터끼리 주고받는게 부담된다. = interconnect → 이를 대체하는 것이 HDFS - 이 때 GFS(Google Fi..
 [airflow] airflow(ubuntu)-mysql 연결하기?
[airflow] airflow(ubuntu)-mysql 연결하기?
mysql 계정 생성하기 id: air/ pw: 1234 생성해볼것 먼저 ubuntu에서 mysql 계정을 사용하여 아래 명령어를 입력하고 들어간다. mysql -u jeeyeon -p (jeeyeon 이라는 계정으로 패스워드 입력해서 접속할게요) jeeyeon 자리에 각자의 mysql 계정을 입력하면 된다. (보통 root를 사용한다. 혹은 root에 버금가는 권한을 가진 계정) (airflow-env) ubuntu@JeeYeon:~$ mysql -u jeeyeon -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 19 Server version: 8.0.34-0ubu..