

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 한장으로끝내는비즈니스모델100
- 비즈니스모델
- 머신러닝
- 올라
- 역설구조
- CAC
- 서말리포켓
- 퍼널분석
- sklearn
- fundbox
- activation
- allra
- 선정산서비스
- pmf
- 데이터분석
- 전환율
- BM분석
- 리텐션
- 팔방이익구조
- retention
- 핀테크
- model_selection
- 코호트
- mysql설치 #mysql #mysqluser #mysqlworkbench
- 인게이지먼트
- 바로팜
- 셀프스토리지
- 활성화
- 그로스해킹
- aarrr
- Today
- Total
데이터로그😎
[FCL] Full Connected Layer 본문
2023.12.02 - [딥러닝] - [CNN] FCL vs CNN
[CNN] FCL vs CNN
✔️FCL (Full Connected Layer, 완전 연결층) 특성 공간에 있는 전역패턴을 학습 전 레이어에서 추출된 특징 맵(feature map)을 평탄화(flatten)한 후에 연산을 수행 입력된 이미지를 펴서 *벡터화(Vectorization)
fine-1004.tistory.com
FCL은 특성공간에 있는 전역 패턴을 학습한다. 모든 레이어에서 추출된 Feature map을 평탄화(Flatten)한 후, 연산을 수행한다. 여기서 Flatten이란, 입력된 모든 데이터를 1차원으로 펴서 Vectorization(벡터화)를 진행한다는 의미이다.
지금부터 FCL을 만드는 코드를 같이 살펴보겠다.
🔹데이터 불러오기 (*MNIST)
*MNIST: 60000장의 train 데이터와 10000장의 test 데이터로 이루어진 데이터 세트. 총 7만장의 손글씨(0-9까지). 각 이미지는 28X28의 흑백 이미지. 총 784 픽셀. 각 픽셀은 0~255 범위의 밝기를 가짐.
MNIST 데이터를 불러오면 train data는 6만장, test data는 1만장이다.
이 때, X_train과 X_test데이터의 shape를 확인해보면 모두 3차원이다. (60000, 28, 28) 이런식으로. 당연하다.이미지니까!
그러나 우리는 지금 FCL을 구성해보고있고, FCL의 특징은 데이터를 1차원으로 벡터화하여 연산을 진행한다는 것이었다. 따라서 FCL연산의 결과물은 1차원이다. 그렇기 때문에 성능을 측정할 때 사용할 y_train, y_test데이터는 FCL연산 결과물과의 비교를 통해 성능을 비교할 수 있도록 1차원인 것이다.
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(X_train,y_train),(X_test, y_test) = mnist.load_data()
print(X_train.shape, X_test.shape) # 3차원
print(y_train.shape, y_test.shape) # 1차원
# Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
# 11490434/11490434 [==============================] - 2s 0us/step
# (60000, 28, 28) (10000, 28, 28)
# (60000,) (10000,)
🔹 시각화
MNIST에서 불러온 이미지를 시각화해볼까?
matplotlib을 통해 가능하다. 확인해보면 X_train의 첫번째 데이터는 5인 것을 확인할 수 있다.
FCL 구성 시, 이렇게 28*28의 모양을 갖춘 이미지 데이터를 1차원으로 펴서 연산을 진행한다.
import matplotlib.pyplot as plt
image = X_train[0]
plt.imshow(image,cmap='gray')
plt.show()
🔹FCL 만들기
- 레이어들은 tensorflow.keras.layers 패키지에 모두 들어 있다.
- Flatten Layer: 배치(BATCH)를 제외한 평탄화 단계.
- Dense Layer : Affine연산(신경망의 행렬 내적 계산). Fully Connected
- Dense Layer 파라미터에 activation을 지정 가능하다.
- Activation Layer : 활성화 함수 레이어(선택에 따라서 사용을 안할 수도 있다.)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Input, Dense, Flatten, Activation
# Sequential 모델을 만들 때는 리스트에 레이어를 쌓아놓기만 하면 된다.
model = Sequential([
Input(shape=(28, 28)), # 입력층. 배치 크기(N)를 제외한 나머지 데이터의 shape 입력
Flatten(), # 평탄화 층. 배치 사이즈를 제외한 나머지 차원을 평탄화
# Fully Connected 구성
#### HIDDEN LAYER ####
Dense(512, activation='relu'),
Dense(256, activation='relu'),
Dense(128, activation='relu'),
Dense(64, activation='relu'),
######################
# 출력층. 숫자는 0 ~ 9 까지 10개 이므로 출력층의 뉴런의 개수는 10개,
# ACTIVATION FUNCTION은 SOFTMAX
# 출력층 숫자 = 분류되길 원하는 클래스 종류 (개수)
Dense(10, activation='softmax')
])
# 모델 요약
model.summary()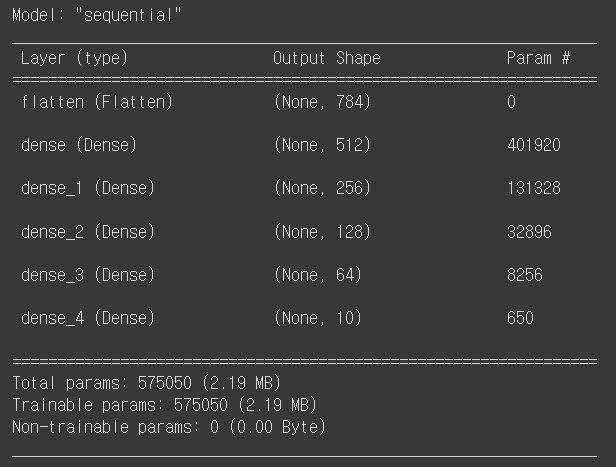
model summary를 살펴보면, 각 dense층에 Param # 이라는 부분이 있다. 이는 각 층의 파라미터를 나타낸다. 각 층에서 왜 이렇게 많은 파라미터가 있는지 한 번 살펴볼까?
512개의 뉴런이 있는 첫번째 dense를 살펴보겠다. 여기서는 파라미터가 총 401920개이다. 왜일까?
아래 이미지를 살펴보면.. 28*28의 입력된 이미지가 flatten단계를 거쳐 총 784라는 1차원 형태가 되었다.
지금 우리가 살펴보고 있는 것은 Full connected layer이다. FCL은 w(가중치)*x(입력값) + b(편향) 이라는 식으로 계산이 되며, 모든 층은 서로 연결이 되어있다. 여기서, 모든 층은 서로 연결되어 있으므로 784*512 개의 가중치가 생긴다. 그리고 편향은 512개의 뉴런 각각에 존재하므로 총 512개이다. 따라서 총 파라미터의 수는 = 784*512 + 512 = 401920이 된다.

🔹최적화 (Compile)
손실함수, 최적화함수, 평가지표를 설정하는 단계이다.
- Loss Function(손실 함수) - MSE, CEE를 쓸지를 결정
- Optimization(최적화 함수) - SGD, ADAM, RMSProps 등을 지정
- 거의 대부분 ADAM, RMSProps 등을 기본으로 사용
- Metrics - 테스트 세트에 대한 평가 기준: acc, recall, precision
① Loss function
- 이진 분류를 수행하는 경우(Binary Classification) : tf.keras.losses.binary_crossentropy
- 출력층의 뉴런이 1개인 경우 (출력값 1개) : MSE with sigmoid
- 출력층의 뉴런이 2개인 경우 (출력값 2개): CEE with softmax ( 제일 자주 사용되는 방법 )
- 다중 분류를 수행하는 경우(Multiclass Classification): 출력층의 뉴런을 클래스의 개수만큼 설정
- Label이 One-Hot Encoding이 되어있지 않은 경우 (ex) [0,1,2,3,…])
-
- sparse_categorical_crossentropy를 사용
- tf.keras.losses.sparse_categorical_crossentropy
- Label이 One-Hot Encoding 되어있는 경우
- categorical_crossentropy를 사용
- tf.keras.losses.categorical_crossentropy
-
- Label이 One-Hot Encoding이 되어있지 않은 경우 (ex) [0,1,2,3,…])
② Optimizer 설정
- sgd- tf.keras.optimizers.SGD()
- rmsprops - tf.keras.optimizers.RMSprop()
- adam - tf.keras.optimizers.Adam() - 일반적으로 제일 많이 사용하는 최적화 기법, 뭘 쓸지 모르겠다면 adam을 선택하세요
③ Metrics 설정
- 테스트(검증) 세트 평가 방법
- 훈련에 영향을 미치는 것이 아닌, 확인 용도의 설정
- 일반적으로는 정확도로 설정: accuracy, acc 중 하나로 설정.
loss_func = tf.keras.losses.sparse_categorical_crossentropy
optm = tf.keras.optimizers.Adam()
metrics = ['acc']
model.compile(
optimizer = optm,
loss = loss_func,
metrics = metrics
)
🔹훈련 (fit)
- num_epochs : 에폭은 "전체 훈련 데이터셋"을 한 번씩 모델에 전달하는 것을 의미. 한 번의 훈련이라고 생각하면 된다.
- batch_size : 미니배치의 크기를 의미
# 훈련용 하이퍼 파라미터 설정
# 에폭, 배치크기
num_epochs = 10
batch_size = 32
model.fit(
X_train, # 훈련 X 데이터(feature)
y_train, # 훈련 y 레이블(target)
batch_size=batch_size,
epochs=num_epochs,
shuffle=True, # 데이터를 섞어 가면서 복잡하게 훈련
validation_split=0.2 # 전체 훈련 데이터 중 검증 세트로 사용할 크기의 비율
)

위 이미지는 훈련의 과정을 보여준다.
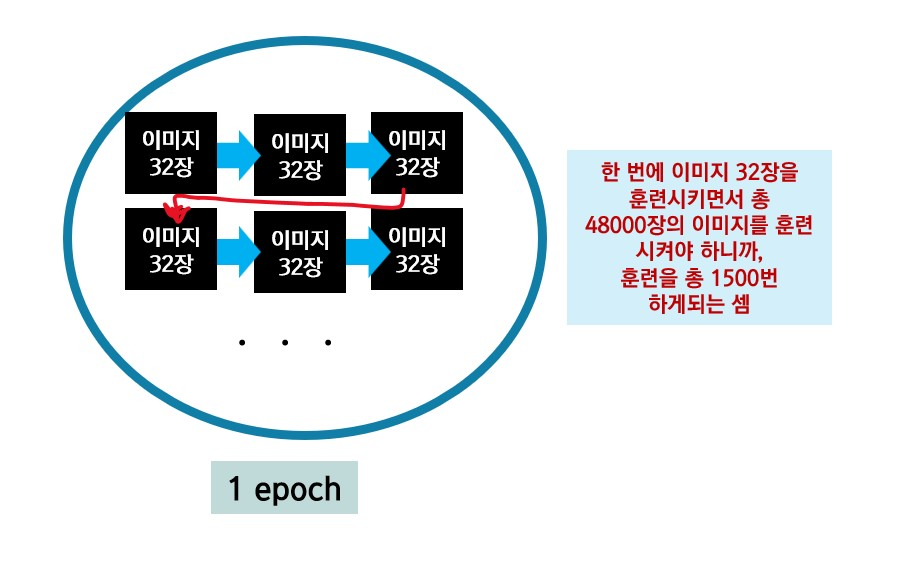
num_epochs을 10으로 설정했기에 총 10번의 훈련이 진행되며, 각 에폭마다 1500번의 훈련이 진행된다. 1500이 갑자기 어디서 튀어나왔냐고?? 설명해보겠다.
train data는 총 60000장이었는데, 위의 코드에서 validataion_split을 통해 이 train data를 다시 train,test데이터로 쪼개서 데이터 중 80%는 train, 20%는 test데이터로 쓰도록 설정했다. 그래서 최종적으로 60000*0.8 = 48000장을 train data로 쓰게 된 것이다.
그래서 이 48000장을 한 에폭동안 훈련을 해야하며, 우리는 미니배치로 훈련을 하기로 했다!
batch_size를 32로 정해서, 한 번에 32장의 데이터를 훈련하는 것이지. 따라서 48000장/32장 = 1500장! 어렵다!
다시 요약해보면, 1에폭에 48000장의 이미지를 훈련한다. 그런데 한 번 훈련할 때 32장씩만 훈련하여, 총 1500번의 훈련을 한 에폭동안 하는 것!!!!!
🔹 최종 평가
model.evaulate(X_test, y_test)
>>>
313/313 [==============================] - 2s 4ms/step - loss: 0.1257 - acc: 0.9697
[0.12566782534122467, 0.9696999788284302]
[ loss value, accuracy value ]'#4. 기타 공부 > #4.3. 딥러닝' 카테고리의 다른 글
| [CNN] Convolutional Neural Network (0) | 2023.12.04 |
|---|---|
| [CNN] FCL vs CNN (0) | 2023.12.02 |
| [DNN] DNN 설계 단계 - ② 손실함수, ③ 최적화 (1) | 2023.12.02 |
| [DNN] 02. DNN 설계 단계 - ① 레이어 설계 (0) | 2023.11.28 |
| [DNN] 01. DNN 기본 용어 (0) | 2023.11.28 |


